 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Object Accuracy for Generative Text-to-Image Synthesis
Paper and Code

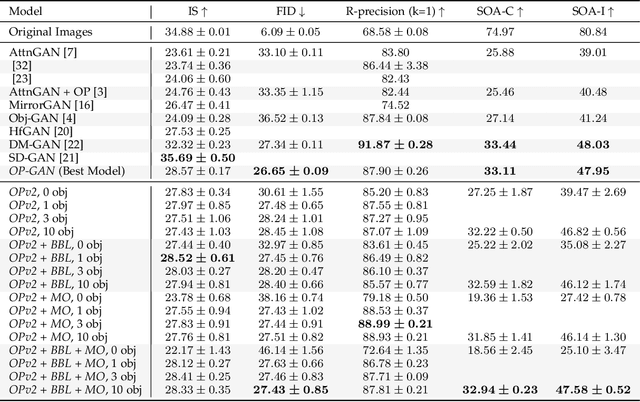

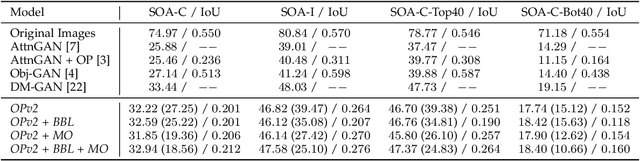
Generative adversarial networks conditioned on simple textual image descriptions are capable of generating realistic-looking images. However, current methods still struggle to generate images based on complex image captions from a heterogeneous domain. Furthermore, quantitatively evaluating these text-to-image synthesis models is still challenging, as most evaluation metrics only judge image quality but not the conformity between the image and its caption. To address the aforementioned challenges we introduce both a new model that explicitly models individual objects within an image and a new evaluation metric called Semantic Object Accuracy (SOA) that specifically evaluates images given an image caption. Our model adds an object pathway to both the generator and the discriminator to explicitly learn features of individual objects. The SOA uses a pre-trained object detector to evaluate if a generated image contains objects that are specifically mentioned in the image caption, e.g. whether an image generated from "a car driving down the street" contains a car. Our evaluation shows that models which explicitly model individual objects outperform models which only model global image characteristics. However, the SOA also shows that despite this increased performance current models still struggle to generate images that contain realistic objects of multiple different domains.