 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Autoencoder for Zero-Shot Learning
Paper and Code
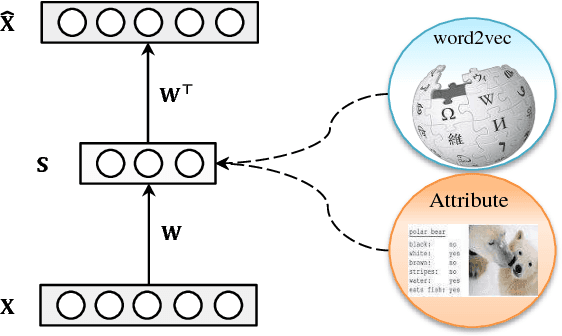
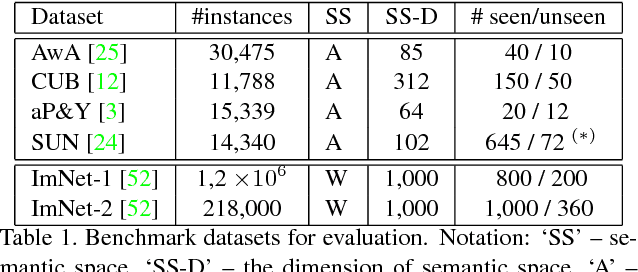
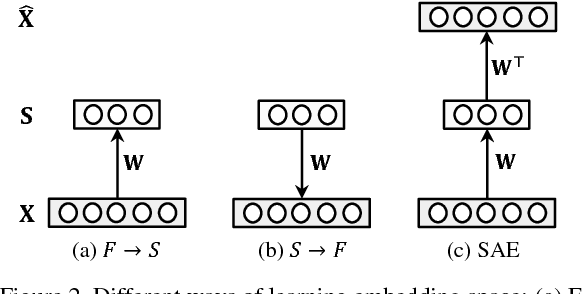
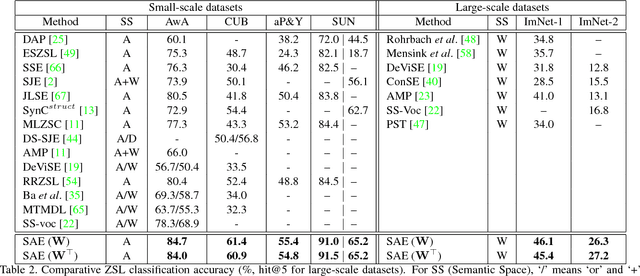
Existing zero-shot learning (ZSL) models typically learn a projection function from a feature space to a semantic embedding space (e.g.~attribute space). However, such a projection function is only concerned with predicting the training seen class semantic representation (e.g.~attribute prediction) or classification. When applied to test data, which in the context of ZSL contains different (unseen) classes without training data, a ZSL model typically suffers from the project domain shift problem. In this work, we present a novel solution to ZSL based on learning a Semantic AutoEncoder (SAE). Taking the encoder-decoder paradigm, an encoder aims to project a visual feature vector into the semantic space as in the existing ZSL models. However, the decoder exerts an additional constraint, that is, the projection/code must be able to reconstruct the original visual feature. We show that with this additional reconstruction constraint, the learned projection function from the seen classes is able to generalise better to the new unseen classes. Importantly, the encoder and decoder are linear and symmetric which enable us to develop an extremely efficient learning algorithm. Extensive experiments on six benchmark datasets demonstrate that the proposed SAE outperforms significantly the existing ZSL models with the additional benefit of lower computational cost. Furthermore, when the SAE is applied to supervised clustering problem, it also beats the state-of-the-art.