 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfie: Self-supervised Pretraining for Image Embedding
Paper and Code
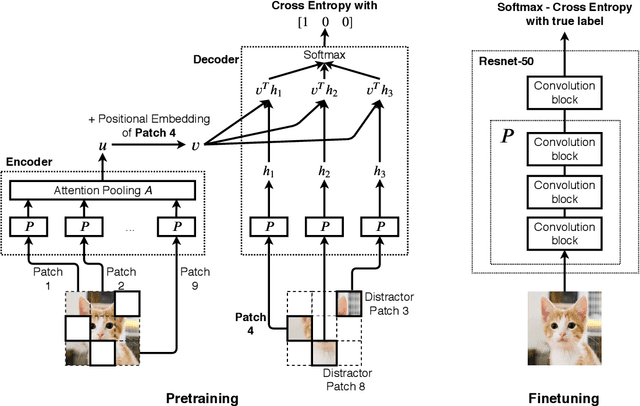
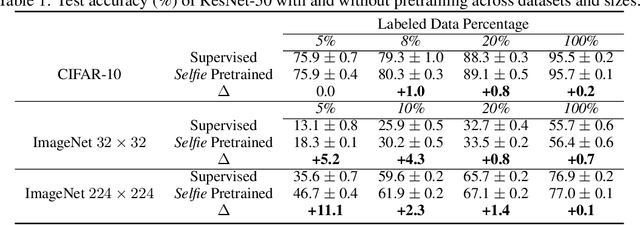

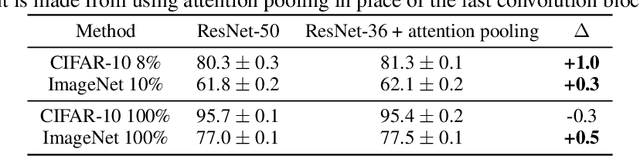
We introduce a pretraining technique called Selfie, which stands for SELFie supervised Image Embedding. Selfie generalizes the concept of masked language modeling of BERT (Devlin et al., 2019) to continuous data, such as images, by making use of the Contrastive Predictive Coding loss (Oord et al., 2018). Given masked-out patches in an input image, our method learns to select the correct patch, among other "distractor" patches sampled from the same image, to fill in the masked location. This classification objective sidesteps the need for predicting exact pixel values of the target patches. The pretraining architecture of Selfie includes a network of convolutional blocks to process patches followed by an attention pooling network to summarize the content of unmasked patches before predicting masked ones. During finetuning, we reuse the convolutional weights found by pretraining. We evaluate Selfie on three benchmarks (CIFAR-10, ImageNet 32 x 32, and ImageNet 224 x 224) with varying amounts of labeled data, from 5% to 100% of the training sets. Our pretraining method provides consistent improvements to ResNet-50 across all settings compared to the standard supervised training of the same network. Notably, on ImageNet 224 x 224 with 60 examples per class (5%), our method improves the mean accuracy of ResNet-50 from 35.6% to 46.7%, an improvement of 11.1 points in absolute accuracy. Our pretraining method also improves ResNet-50 training stability, especially on low data regime, by significantly lowering the standard deviation of test accuracies across different runs.