 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-taught learning of a deep invariant representation for visual tracking via temporal slowness principle
Paper and Code
Apr 14, 2016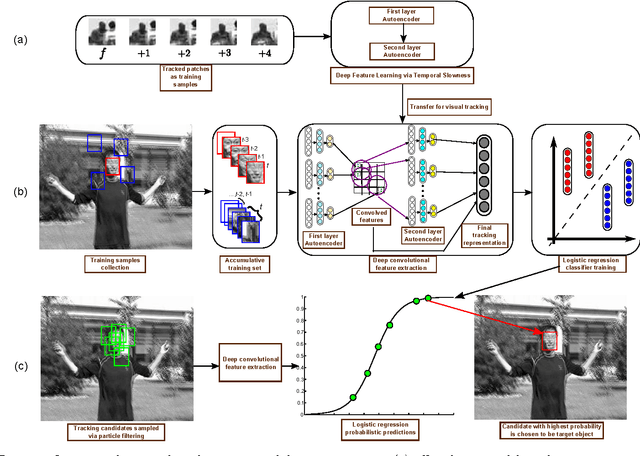

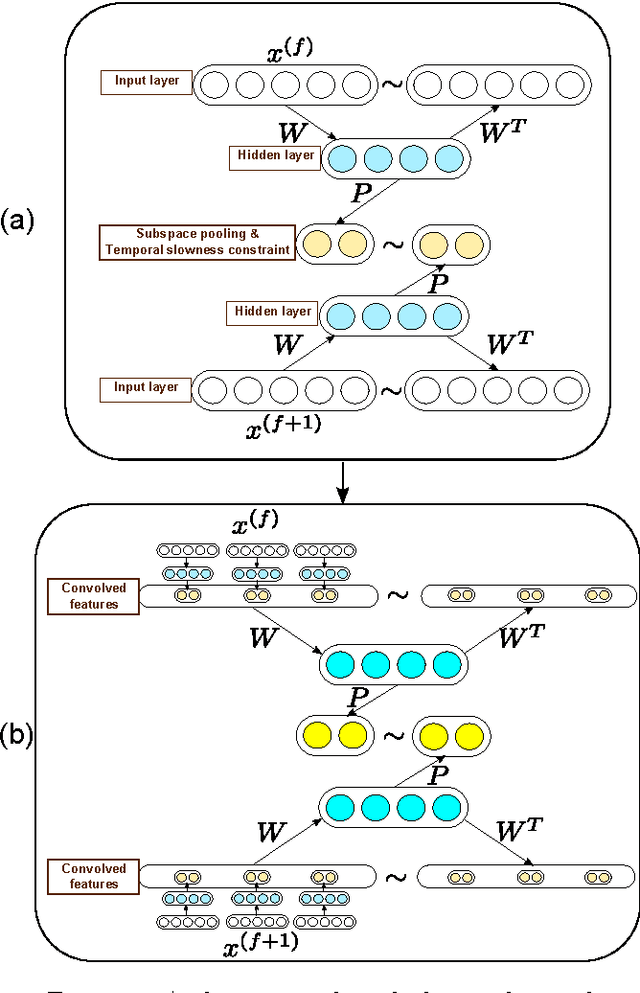

Visual representation is crucial for a visual tracking method's performances. Conventionally, visual representations adopted in visual tracking rely on hand-crafted computer vision descriptors. These descriptors were developed generically without considering tracking-specific information. In this paper, we propose to learn complex-valued invariant representations from tracked sequential image patches, via strong temporal slowness constraint and stacked convolutional autoencoders. The deep slow local representations are learned offline on unlabeled data and transferred to the observational model of our proposed tracker. The proposed observational model retains old training samples to alleviate drift, and collect negative samples which are coherent with target's motion pattern for better discriminative tracking. With the learned representation and online training samples, a logistic regression classifier is adopted to distinguish target from background, and retrained online to adapt to appearance changes. Subsequently, the observational model is integrated into a particle filter framework to peform visual tracking. Experimental results on various challenging benchmark sequences demonstrate that the proposed tracker performs favourably against several state-of-the-art trackers.