 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Spatio-Temporal Representation Learning Using Variable Playback Speed Prediction
Paper and Code
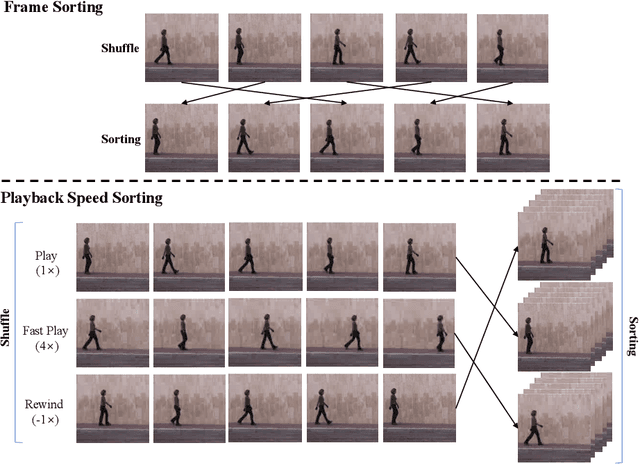

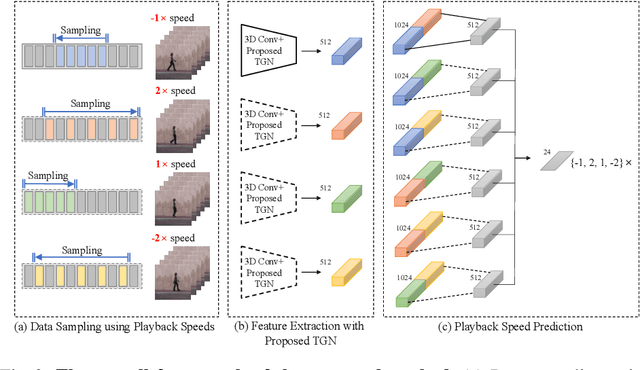

We propose a self-supervised learning method by predicting the variable playback speeds of a video. Without semantic labels, we learn the spatio-temporal representation of the video by leveraging the variations in the visual appearance according to different playback speeds under the assumption of temporal coherence. To learn the spatio-temporal variations in the entire video, we have not only predicted a single playback speed but also generated clips of various playback speeds with randomized starting points. We then train a 3D convolutional network by solving the formulation that sorts the shuffled clips by their playback speed. In this case, the playback speed includes both forward and reverse directions; hence the visual representation can be successfully learned from the directional dynamics of the video. We also propose a novel layer-dependable temporal group normalization method that can be applied to 3D convolutional networks to improve the representation learning performance where we divide the temporal features into several groups and normalize each one using the different corresponding parameters. We validate the effectiveness of the proposed method by fine-tuning it to the action recognition task. The experimental results show that the proposed method outperforms state-of-the-art self-supervised learning methods in action recognition.