 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Semi-supervised Learning for Data Labeling and Quality Evaluation
Paper and Code
Nov 22, 2021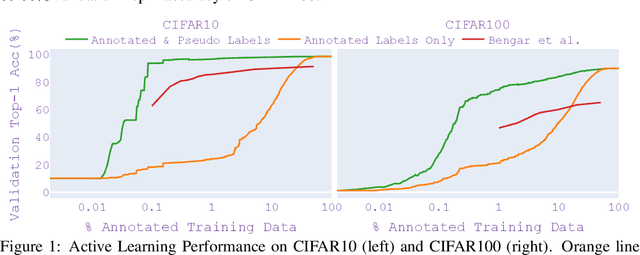
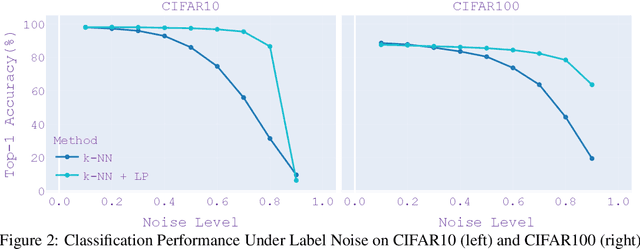
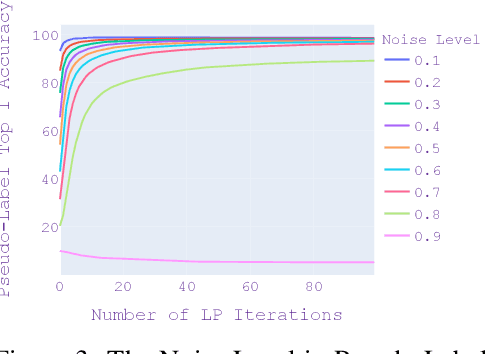
As the adoption of deep learning techniques in industrial applications grows with increasing speed and scale, successful deployment of deep learning models often hinges on the availability, volume, and quality of annotated data. In this paper, we tackle the problems of efficient data labeling and annotation verification under the human-in-the-loop setting. We showcase that the latest advancements in the field of self-supervised visual representation learning can lead to tools and methods that benefit the curation and engineering of natural image datasets, reducing annotation cost and increasing annotation quality. We propose a unifying framework by leveraging self-supervised semi-supervised learning and use it to construct workflows for data labeling and annotation verification tasks. We demonstrate the effectiveness of our workflows over existing methodologies. On active learning task, our method achieves 97.0% Top-1 Accuracy on CIFAR10 with 0.1% annotated data, and 83.9% Top-1 Accuracy on CIFAR100 with 10% annotated data. When learning with 50% of wrong labels, our method achieves 97.4% Top-1 Accuracy on CIFAR10 and 85.5% Top-1 Accuracy on CIFAR100.