 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Multi-actor Social Activity Understanding in Streaming Videos
Paper and Code
Jun 20, 2024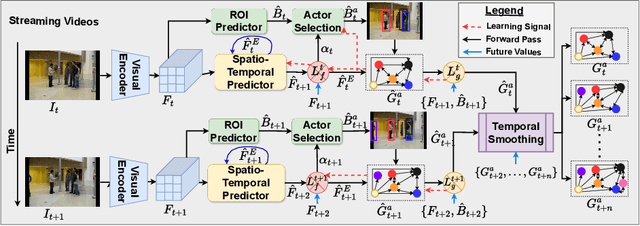
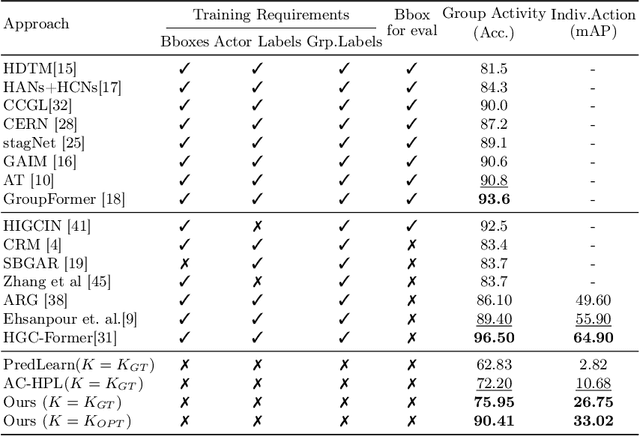


This work addresses the problem of Social Activity Recognition (SAR), a critical component in real-world tasks like surveillance and assistive robotics. Unlike traditional event understanding approaches, SAR necessitates modeling individual actors' appearance and motions and contextualizing them within their social interactions. Traditional action localization methods fall short due to their single-actor, single-action assumption. Previous SAR research has relied heavily on densely annotated data, but privacy concerns limit their applicability in real-world settings. In this work, we propose a self-supervised approach based on multi-actor predictive learning for SAR in streaming videos. Using a visual-semantic graph structure, we model social interactions, enabling relational reasoning for robust performance with minimal labeled data. The proposed framework achieves competitive performance on standard group activity recognition benchmarks. Evaluation on three publicly available action localization benchmarks demonstrates its generalizability to arbitrary action localization.