 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Contrastive Learning for Efficient User Satisfaction Prediction in Conversational Agents
Paper and Code
Oct 21, 2020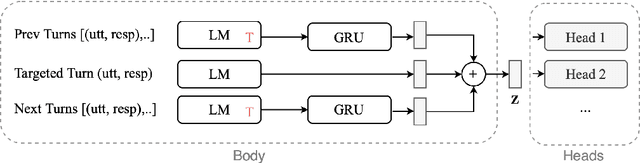
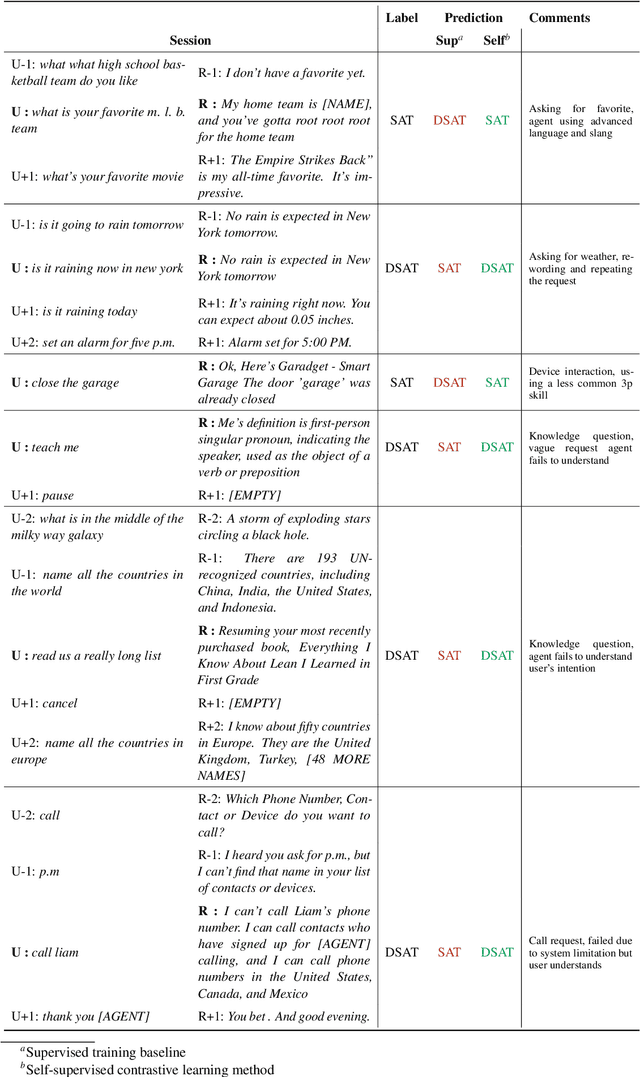


Turn-level user satisfaction is one of the most important performance metrics for conversational agents. It can be used to monitor the agent's performance and provide insights about defective user experiences. Moreover, a powerful satisfaction model can be used as an objective function that a conversational agent continuously optimizes for. While end-to-end deep learning has shown promising results, having access to a large number of reliable annotated samples required by these methods remains challenging. In a large-scale conversational system, there is a growing number of newly developed skills, making the traditional data collection, annotation, and modeling process impractical due to the required annotation costs as well as the turnaround times. In this paper, we suggest a self-supervised contrastive learning approach that leverages the pool of unlabeled data to learn user-agent interactions. We show that the pre-trained models using the self-supervised objective are transferable to the user satisfaction prediction. In addition, we propose a novel few-shot transfer learning approach that ensures better transferability for very small sample sizes. The suggested few-shot method does not require any inner loop optimization process and is scalable to very large datasets and complex models. Based on our experiments using real-world data from a large-scale commercial system, the suggested approach is able to significantly reduce the required number of annotations, while improving the generalization on unseen out-of-domain skills.