 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised 3D Human Pose Estimation in Static Video Via Neural Rendering
Paper and Code
Oct 10, 2022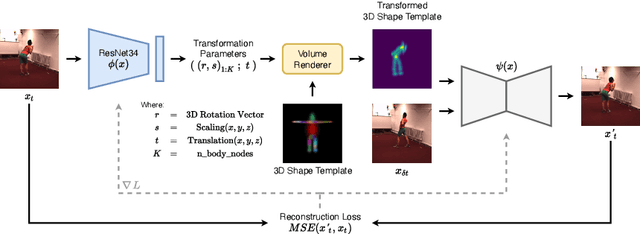
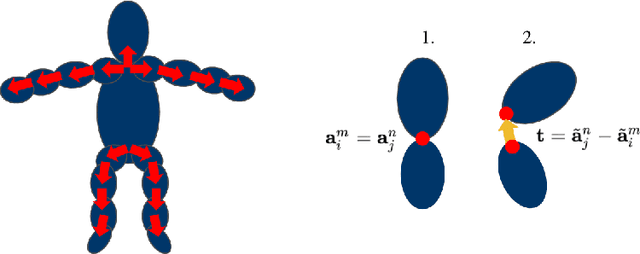
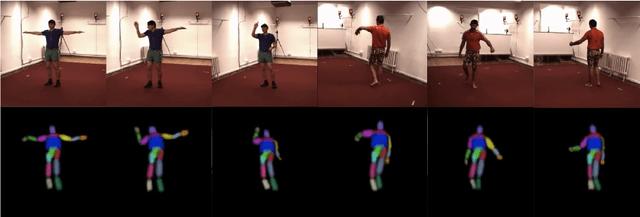
Inferring 3D human pose from 2D images is a challenging and long-standing problem in the field of computer vision with many applications including motion capture, virtual reality, surveillance or gait analysis for sports and medicine. We present preliminary results for a method to estimate 3D pose from 2D video containing a single person and a static background without the need for any manual landmark annotations. We achieve this by formulating a simple yet effective self-supervision task: our model is required to reconstruct a random frame of a video given a frame from another timepoint and a rendered image of a transformed human shape template. Crucially for optimisation, our ray casting based rendering pipeline is fully differentiable, enabling end to end training solely based on the reconstruction task.