 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Prompting Large Language Models for Open-Domain QA
Paper and Code
Dec 16, 2022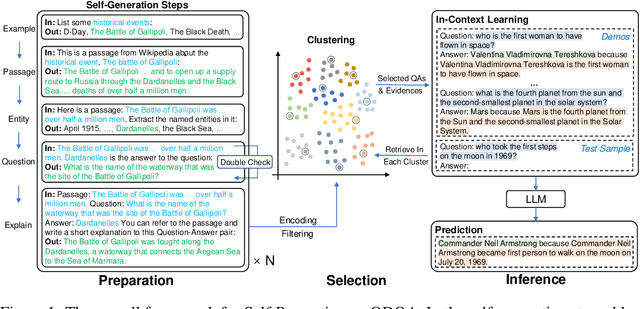



Open-Domain Question Answering (ODQA) requires models to answer factoid questions with no context given. The common way for this task is to train models on a large-scale annotated dataset to retrieve related documents and generate answers based on these documents. In this paper, we show that the ODQA architecture can be dramatically simplified by treating Large Language Models (LLMs) as a knowledge corpus and propose a Self-Prompting framework for LLMs to perform ODQA so as to eliminate the need for training data and external knowledge corpus. Concretely, we firstly generate multiple pseudo QA pairs with background passages and one-sentence explanations for these QAs by prompting LLMs step by step and then leverage the generated QA pairs for in-context learning. Experimental results show our method surpasses previous state-of-the-art methods by +8.8 EM averagely on three widely-used ODQA datasets, and even achieves comparable performance with several retrieval-augmented fine-tuned models.