 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Pre-training with Masked Autoencoders for Medical Image Analysis
Paper and Code
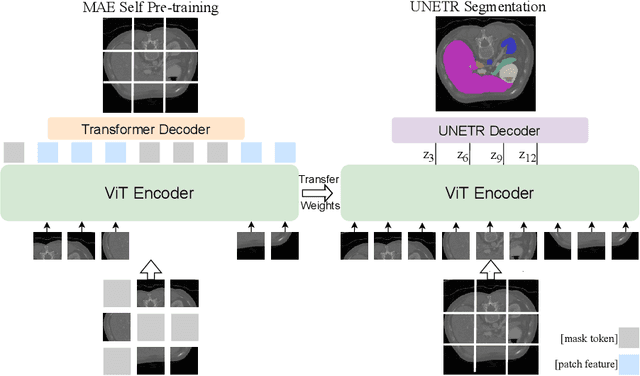
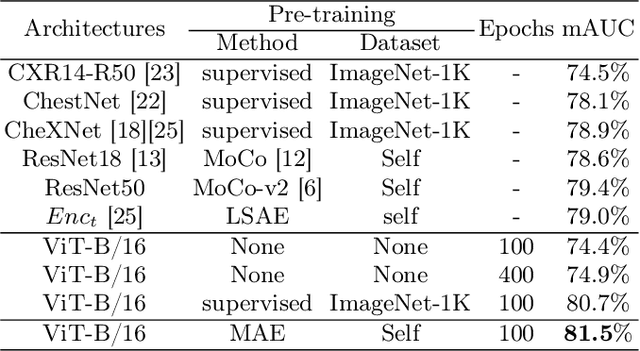
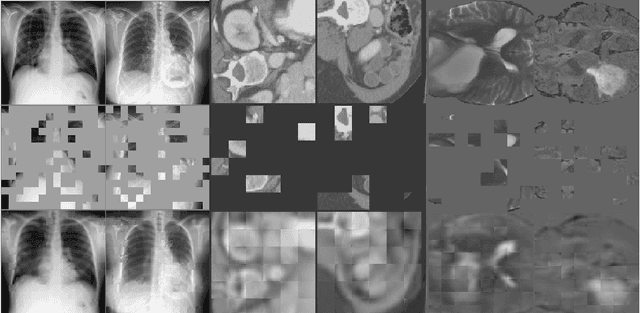
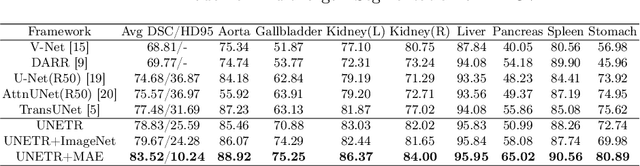
Masked Autoencoder (MAE) has recently been shown to be effective in pre-training Vision Transformers (ViT) for natural image analysis. By performing the pretext task of reconstructing the original image from only partial observations, the encoder, which is a ViT, is encouraged to aggregate contextual information to infer content in masked image regions. We believe that this context aggregation ability is also essential to the medical image domain where each anatomical structure is functionally and mechanically connected to other structures and regions. However, there is no ImageNet-scale medical image dataset for pre-training. Thus, in this paper, we investigate a self pre-training paradigm with MAE for medical images, i.e., models are pre-trained on the same target dataset. To validate the MAE self pre-training, we consider three diverse medical image tasks including chest X-ray disease classification, CT abdomen multi-organ segmentation and MRI brain tumor segmentation. It turns out MAE self pre-training benefits all the tasks markedly. Specifically, the mAUC on lung disease classification is increased by 9.4%. The average DSC on brain tumor segmentation is improved from 77.4% to 78.9%. Most interestingly, on the small-scale multi-organ segmentation dataset (N=30), the average DSC improves from 78.8% to 83.5% and the HD95 is reduced by 60%, indicating its effectiveness in limited data scenarios. The segmentation and classification results reveal the promising potential of MAE self pre-training for medical image analysis.