 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attentive 3D Human Pose and Shape Estimation from Videos
Paper and Code
Mar 26, 2021
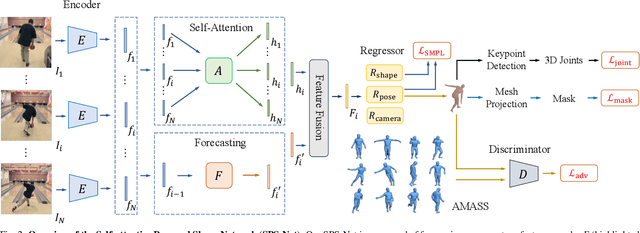

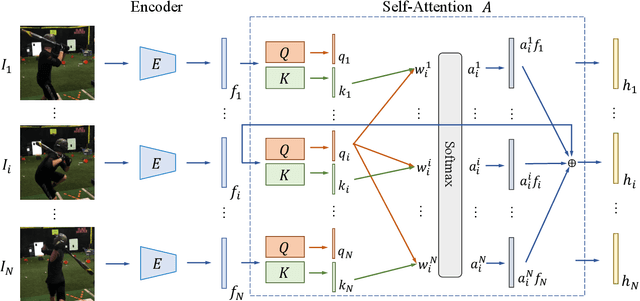
We consider the task of estimating 3D human pose and shape from videos. While existing frame-based approaches have made significant progress, these methods are independently applied to each image, thereby often leading to inconsistent predictions. In this work, we present a video-based learning algorithm for 3D human pose and shape estimation. The key insights of our method are two-fold. First, to address the inconsistent temporal prediction issue, we exploit temporal information in videos and propose a self-attention module that jointly considers short-range and long-range dependencies across frames, resulting in temporally coherent estimations. Second, we model human motion with a forecasting module that allows the transition between adjacent frames to be smooth. We evaluate our method on the 3DPW, MPI-INF-3DHP, and Human3.6M datasets. Extensive experimental results show that our algorithm performs favorably against the state-of-the-art methods.