 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation with Super Images: A New 2D Perspective on 3D Medical Image Analysis
Paper and Code
May 05, 2022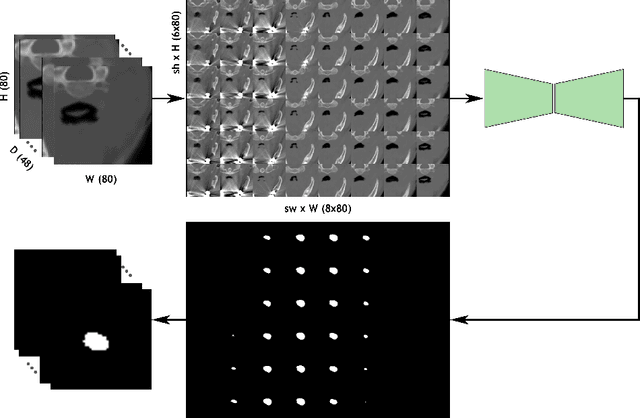
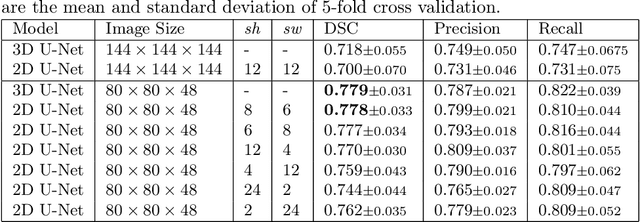

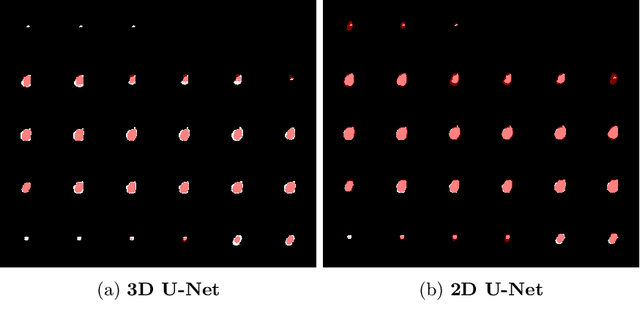
Deep learning is showing an increasing number of audience in medical imaging research. In the segmentation task of medical images, we oftentimes rely on volumetric data, and thus require the use of 3D architectures which are praised for their ability to capture more features from the depth dimension. Yet, these architectures are generally more ineffective in time and compute compared to their 2D counterpart on account of 3D convolutions, max pooling, up-convolutions, and other operations used in these networks. Moreover, there are limited to no 3D pretrained model weights, and pretraining is generally challenging. To alleviate these issues, we propose to cast volumetric data to 2D super images and use 2D networks for the segmentation task. The method processes the 3D image by stitching slices side-by-side to generate a super resolution image. While the depth information is lost, we expect that deep neural networks can still capture and learn these features. Our goal in this work is to introduce a new perspective when dealing with volumetric data, and test our hypothesis using vanilla networks. We hope that this approach, while achieving close enough results to 3D networks using only 2D counterparts, can attract more related research in the future, especially in medical image analysis since volumetric data is comparably limited.