 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Sarcasm Through Different Eyes: Analyzing Multimodal Sarcasm Perception in Large Vision-Language Models
Paper and Code



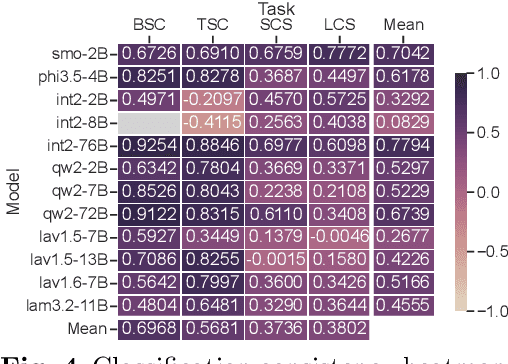
With the advent of large vision-language models (LVLMs) demonstrating increasingly human-like abilities, a pivotal question emerges: do different LVLMs interpret multimodal sarcasm differently, and can a single model grasp sarcasm from multiple perspectives like humans? To explore this, we introduce an analytical framework using systematically designed prompts on existing multimodal sarcasm datasets. Evaluating 12 state-of-the-art LVLMs over 2,409 samples, we examine interpretive variations within and across models, focusing on confidence levels, alignment with dataset labels, and recognition of ambiguous "neutral" cases. Our findings reveal notable discrepancies -- across LVLMs and within the same model under varied prompts. While classification-oriented prompts yield higher internal consistency, models diverge markedly when tasked with interpretive reasoning. These results challenge binary labeling paradigms by highlighting sarcasm's subjectivity. We advocate moving beyond rigid annotation schemes toward multi-perspective, uncertainty-aware modeling, offering deeper insights into multimodal sarcasm comprehension. Our code and data are available at: https://github.com/CoderChen01/LVLMSarcasmAnalysis