 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEDA: Self-Ensembling ViT with Defensive Distillation and Adversarial Training for robust Chest X-rays Classification
Paper and Code
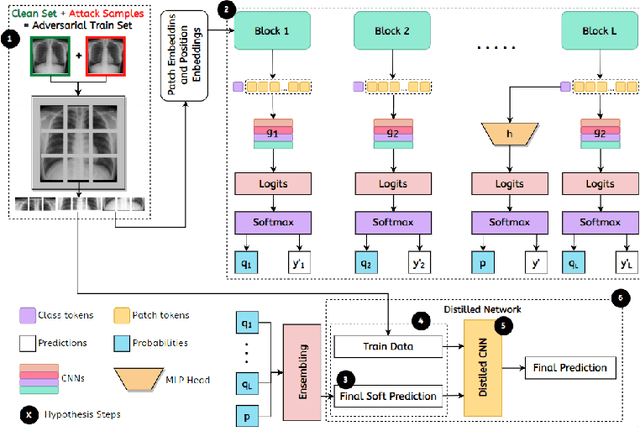



Deep Learning methods have recently seen increased adoption in medical imaging applications. However, elevated vulnerabilities have been explored in recent Deep Learning solutions, which can hinder future adoption. Particularly, the vulnerability of Vision Transformer (ViT) to adversarial, privacy, and confidentiality attacks raise serious concerns about their reliability in medical settings. This work aims to enhance the robustness of self-ensembling ViTs for the tuberculosis chest x-ray classification task. We propose Self-Ensembling ViT with defensive Distillation and Adversarial training (SEDA). SEDA utilizes efficient CNN blocks to learn spatial features with various levels of abstraction from feature representations extracted from intermediate ViT blocks, that are largely unaffected by adversarial perturbations. Furthermore, SEDA leverages adversarial training in combination with defensive distillation for improved robustness against adversaries. Training using adversarial examples leads to better model generalizability and improves its ability to handle perturbations. Distillation using soft probabilities introduces uncertainty and variation into the output probabilities, making it more difficult for adversarial and privacy attacks. Extensive experiments performed with the proposed architecture and training paradigm on publicly available Tuberculosis x-ray dataset shows SOTA efficacy of SEDA compared to SEViT in terms of computational efficiency with 70x times lighter framework and enhanced robustness of +9%.