 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScoring of Large-Margin Embeddings for Speaker Verification: Cosine or PLDA?
Paper and Code
Apr 11, 2022
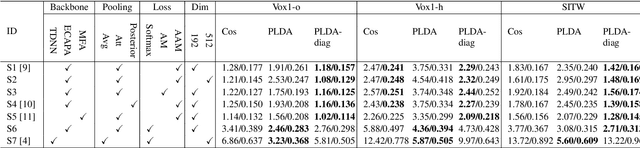


The emergence of large-margin softmax cross-entropy losses in training deep speaker embedding neural networks has triggered a gradual shift from parametric back-ends to a simpler cosine similarity measure for speaker verification. Popular parametric back-ends include the probabilistic linear discriminant analysis (PLDA) and its variants. This paper investigates the properties of margin-based cross-entropy losses leading to such a shift and aims to find scoring back-ends best suited for speaker verification. In addition, we revisit the pre-processing techniques which have been widely used in the past and assess their effectiveness on large-margin embeddings. Experiments on the state-of-the-art ECAPA-TDNN networks trained with various large-margin softmax cross-entropy losses show a substantial increment in intra-speaker compactness making the conventional PLDA superfluous. In this regard, we found that constraining the within-speaker covariance matrix could improve the performance of the PLDA. It is demonstrated through a series of experiments on the VoxCeleb-1 and SITW core-core test sets with 40.8% equal error rate (EER) reduction and 35.1% minimum detection cost (minDCF) reduction. It also outperforms cosine scoring consistently with reductions in EER and minDCF by 10.9% and 4.9%, respectively.