 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchedule Based Temporal Difference Algorithms
Paper and Code
Nov 23, 2021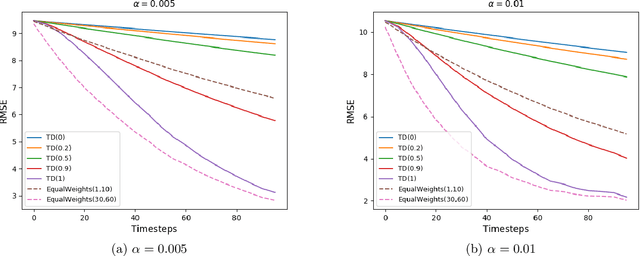

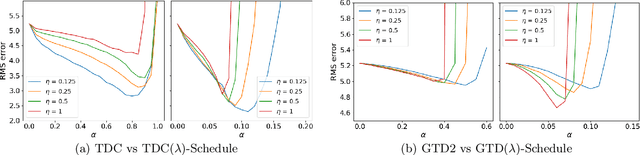
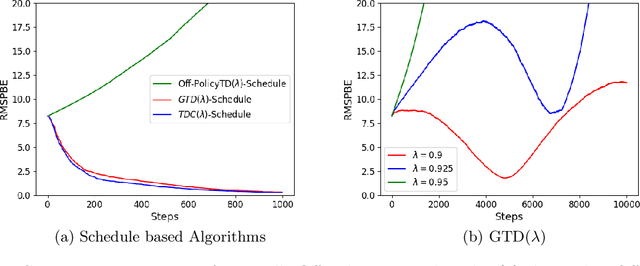
Learning the value function of a given policy from data samples is an important problem in Reinforcement Learning. TD($\lambda$) is a popular class of algorithms to solve this problem. However, the weights assigned to different $n$-step returns in TD($\lambda$), controlled by the parameter $\lambda$, decrease exponentially with increasing $n$. In this paper, we present a $\lambda$-schedule procedure that generalizes the TD($\lambda$) algorithm to the case when the parameter $\lambda$ could vary with time-step. This allows flexibility in weight assignment, i.e., the user can specify the weights assigned to different $n$-step returns by choosing a sequence $\{\lambda_t\}_{t \geq 1}$. Based on this procedure, we propose an on-policy algorithm - TD($\lambda$)-schedule, and two off-policy algorithms - GTD($\lambda$)-schedule and TDC($\lambda$)-schedule, respectively. We provide proofs of almost sure convergence for all three algorithms under a general Markov noise framework.