 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneGraMMi: Scene Graph-boosted Hybrid-fusion for Multi-Modal Misinformation Veracity Prediction
Paper and Code
Oct 20, 2024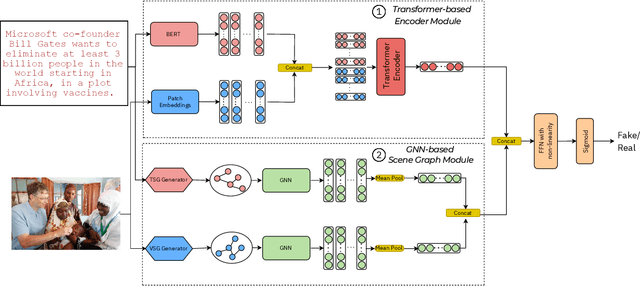

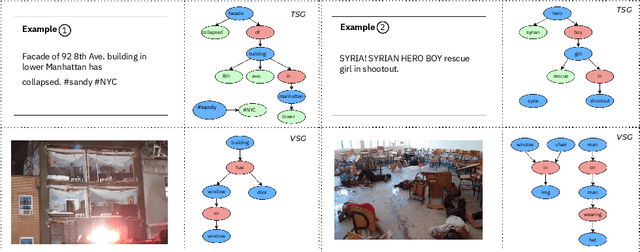
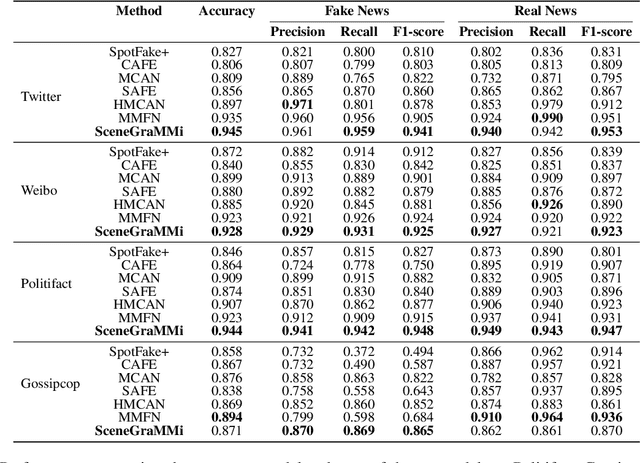
Misinformation undermines individual knowledge and affects broader societal narratives. Despite growing interest in the research community in multi-modal misinformation detection, existing methods exhibit limitations in capturing semantic cues, key regions, and cross-modal similarities within multi-modal datasets. We propose SceneGraMMi, a Scene Graph-boosted Hybrid-fusion approach for Multi-modal Misinformation veracity prediction, which integrates scene graphs across different modalities to improve detection performance. Experimental results across four benchmark datasets show that SceneGraMMi consistently outperforms state-of-the-art methods. In a comprehensive ablation study, we highlight the contribution of each component, while Shapley values are employed to examine the explainability of the model's decision-making process.