 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCAM! Transferring humans between images with Semantic Cross Attention Modulation
Paper and Code
Oct 10, 2022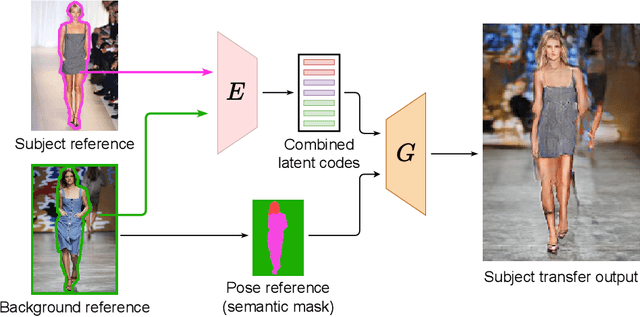

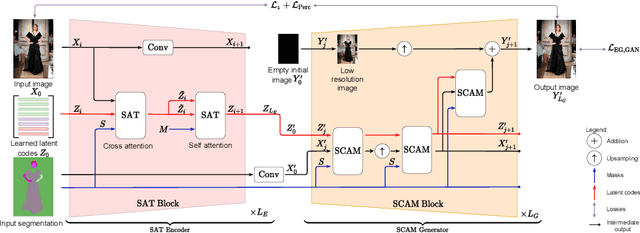
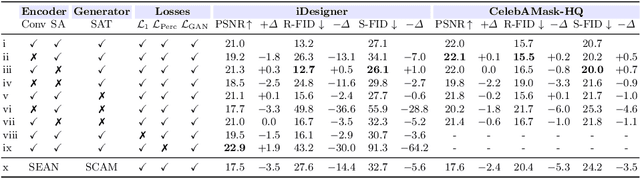
A large body of recent work targets semantically conditioned image generation. Most such methods focus on the narrower task of pose transfer and ignore the more challenging task of subject transfer that consists in not only transferring the pose but also the appearance and background. In this work, we introduce SCAM (Semantic Cross Attention Modulation), a system that encodes rich and diverse information in each semantic region of the image (including foreground and background), thus achieving precise generation with emphasis on fine details. This is enabled by the Semantic Attention Transformer Encoder that extracts multiple latent vectors for each semantic region, and the corresponding generator that exploits these multiple latents by using semantic cross attention modulation. It is trained only using a reconstruction setup, while subject transfer is performed at test time. Our analysis shows that our proposed architecture is successful at encoding the diversity of appearance in each semantic region. Extensive experiments on the iDesigner and CelebAMask-HD datasets show that SCAM outperforms SEAN and SPADE; moreover, it sets the new state of the art on subject transfer.