 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling up Differentially Private Deep Learning with Fast Per-Example Gradient Clipping
Paper and Code
Sep 07, 2020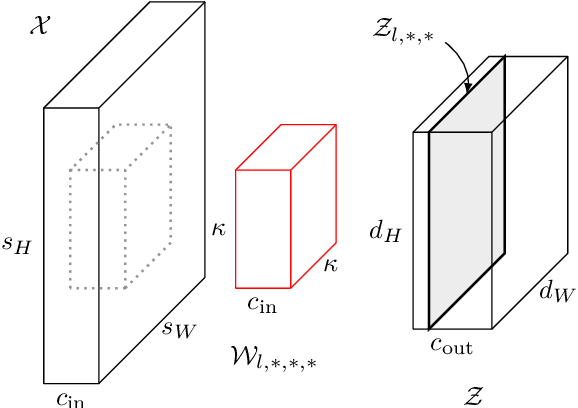



Recent work on Renyi Differential Privacy has shown the feasibility of applying differential privacy to deep learning tasks. Despite their promise, however, differentially private deep networks often lag far behind their non-private counterparts in accuracy, showing the need for more research in model architectures, optimizers, etc. One of the barriers to this expanded research is the training time -- often orders of magnitude larger than training non-private networks. The reason for this slowdown is a crucial privacy-related step called "per-example gradient clipping" whose naive implementation undoes the benefits of batch training with GPUs. By analyzing the back-propagation equations we derive new methods for per-example gradient clipping that are compatible with auto-differentiation (e.g., in PyTorch and TensorFlow) and provide better GPU utilization. Our implementation in PyTorch showed significant training speed-ups (by factors of 54x - 94x for training various models with batch sizes of 128). These techniques work for a variety of architectural choices including convolutional layers, recurrent networks, attention, residual blocks, etc.