 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-Robust Timely Asynchronous Decentralized Learning
Paper and Code
Apr 30, 2024


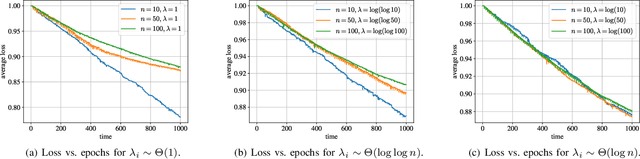
We consider an asynchronous decentralized learning system, which consists of a network of connected devices trying to learn a machine learning model without any centralized parameter server. The users in the network have their own local training data, which is used for learning across all the nodes in the network. The learning method consists of two processes, evolving simultaneously without any necessary synchronization. The first process is the model update, where the users update their local model via a fixed number of stochastic gradient descent steps. The second process is model mixing, where the users communicate with each other via randomized gossiping to exchange their models and average them to reach consensus. In this work, we investigate the staleness criteria for such a system, which is a sufficient condition for convergence of individual user models. We show that for network scaling, i.e., when the number of user devices $n$ is very large, if the gossip capacity of individual users scales as $\Omega(\log n)$, we can guarantee the convergence of user models in finite time. Furthermore, we show that the bounded staleness can only be guaranteed by any distributed opportunistic scheme by $\Omega(n)$ scaling.