 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale Normalized Image Pyramids with AutoFocus for Object Detection
Paper and Code
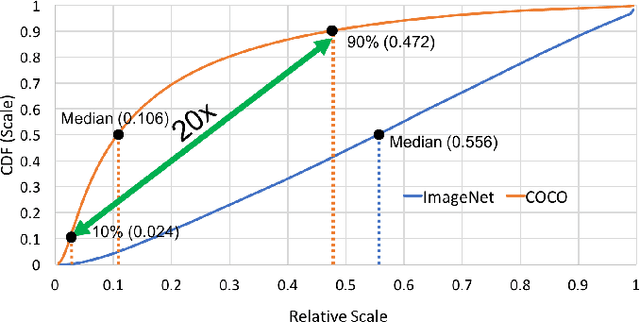

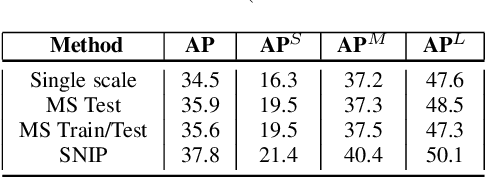
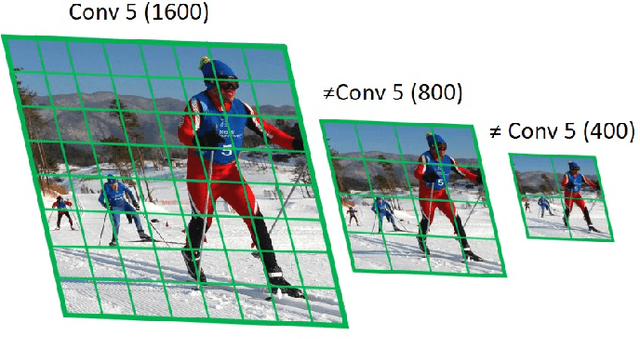
We present an efficient foveal framework to perform object detection. A scale normalized image pyramid (SNIP) is generated that, like human vision, only attends to objects within a fixed size range at different scales. Such a restriction of objects' size during training affords better learning of object-sensitive filters, and therefore, results in better accuracy. However, the use of an image pyramid increases the computational cost. Hence, we propose an efficient spatial sub-sampling scheme which only operates on fixed-size sub-regions likely to contain objects (as object locations are known during training). The resulting approach, referred to as Scale Normalized Image Pyramid with Efficient Resampling or SNIPER, yields up to 3 times speed-up during training. Unfortunately, as object locations are unknown during inference, the entire image pyramid still needs processing. To this end, we adopt a coarse-to-fine approach, and predict the locations and extent of object-like regions which will be processed in successive scales of the image pyramid. Intuitively, it's akin to our active human-vision that first skims over the field-of-view to spot interesting regions for further processing and only recognizes objects at the right resolution. The resulting algorithm is referred to as AutoFocus and results in a 2.5-5 times speed-up during inference when used with SNIP.