 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Statistical Inference of Photometric Redshift via Data Subsampling
Paper and Code
Apr 01, 2021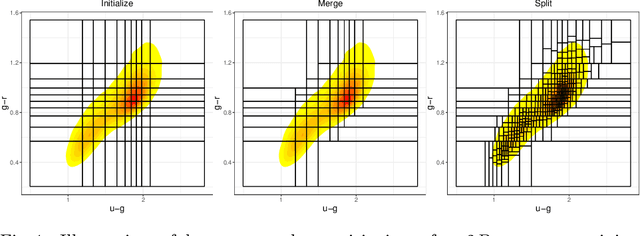
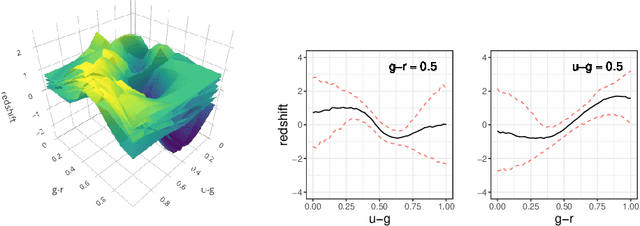
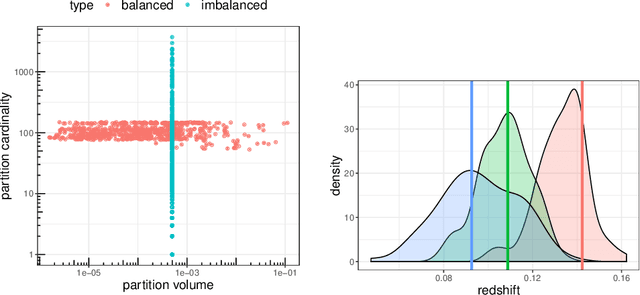
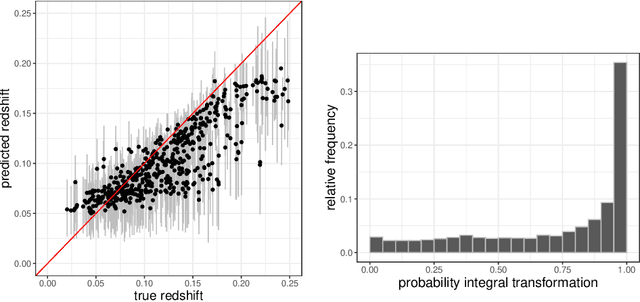
Handling big data has largely been a major bottleneck in traditional statistical models. Consequently, when accurate point prediction is the primary target, machine learning models are often preferred over their statistical counterparts for bigger problems. But full probabilistic statistical models often outperform other models in quantifying uncertainties associated with model predictions. We develop a data-driven statistical modeling framework that combines the uncertainties from an ensemble of statistical models learned on smaller subsets of data carefully chosen to account for imbalances in the input space. We demonstrate this method on a photometric redshift estimation problem in cosmology, which seeks to infer a distribution of the redshift -- the stretching effect in observing the light of far-away galaxies -- given multivariate color information observed for an object in the sky. Our proposed method performs balanced partitioning, graph-based data subsampling across the partitions, and training of an ensemble of Gaussian process models.