 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Multi-Class Gaussian Process Classification using Expectation Propagation
Paper and Code
Jun 22, 2017
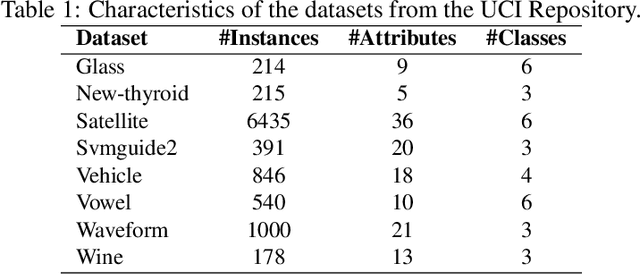


This paper describes an expectation propagation (EP) method for multi-class classification with Gaussian processes that scales well to very large datasets. In such a method the estimate of the log-marginal-likelihood involves a sum across the data instances. This enables efficient training using stochastic gradients and mini-batches. When this type of training is used, the computational cost does not depend on the number of data instances $N$. Furthermore, extra assumptions in the approximate inference process make the memory cost independent of $N$. The consequence is that the proposed EP method can be used on datasets with millions of instances. We compare empirically this method with alternative approaches that approximate the required computations using variational inference. The results show that it performs similar or even better than these techniques, which sometimes give significantly worse predictive distributions in terms of the test log-likelihood. Besides this, the training process of the proposed approach also seems to converge in a smaller number of iterations.