Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Inference for Latent Dirichlet Allocation
Paper and Code
Sep 25, 2009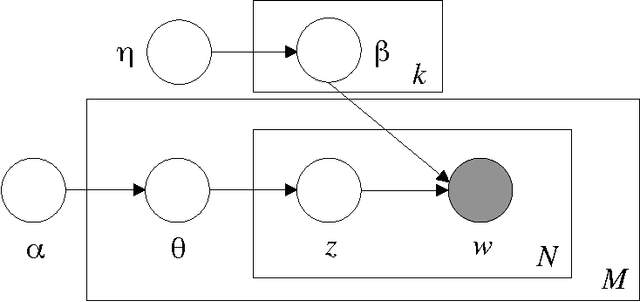


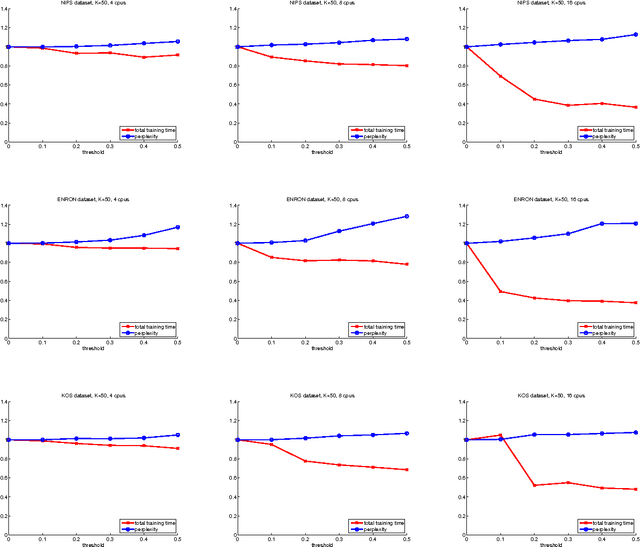
We investigate the problem of learning a topic model - the well-known Latent Dirichlet Allocation - in a distributed manner, using a cluster of C processors and dividing the corpus to be learned equally among them. We propose a simple approximated method that can be tuned, trading speed for accuracy according to the task at hand. Our approach is asynchronous, and therefore suitable for clusters of heterogenous machines.
View paper on