 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamplets: A new paradigm for data compression
Paper and Code
Jul 22, 2021
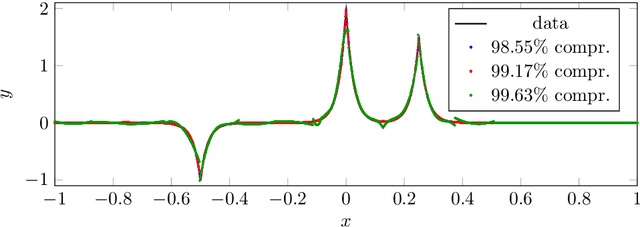
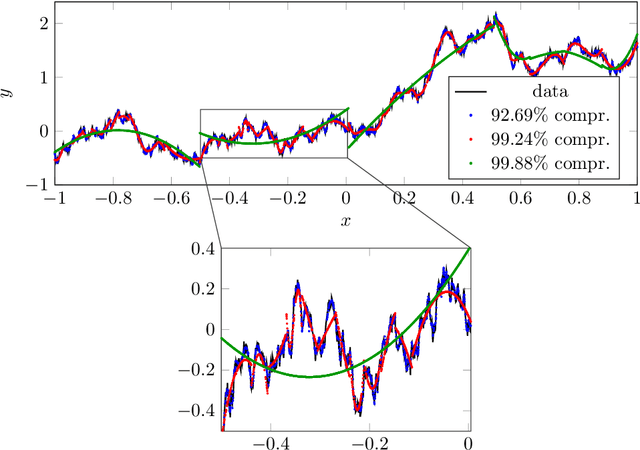

In this article, we introduce the concept of samplets by transferring the construction of Tausch-White wavelets to the realm of data. This way we obtain a multilevel representation of discrete data which directly enables data compression, detection of singularities and adaptivity. Applying samplets to represent kernel matrices, as they arise in kernel based learning or Gaussian process regression, we end up with quasi-sparse matrices. By thresholding small entries, these matrices are compressible to O(N log N) relevant entries, where N is the number of data points. This feature allows for the use of fill-in reducing reorderings to obtain a sparse factorization of the compressed matrices. Besides the comprehensive introduction to samplets and their properties, we present extensive numerical studies to benchmark the approach. Our results demonstrate that samplets mark a considerable step in the direction of making large data sets accessible for analysis.