 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Efficient Stochastic Gradient Iterative Hard Thresholding Method for Stochastic Sparse Linear Regression with Limited Attribute Observation
Paper and Code
Sep 05, 2018
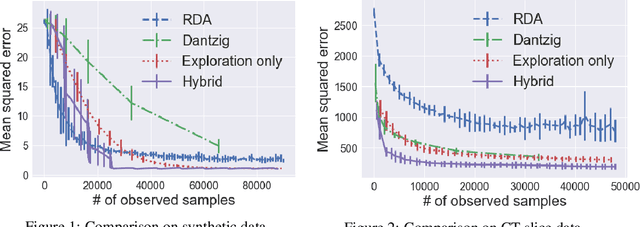
We develop new stochastic gradient methods for efficiently solving sparse linear regression in a partial attribute observation setting, where learners are only allowed to observe a fixed number of actively chosen attributes per example at training and prediction times. It is shown that the methods achieve essentially a sample complexity of $O(1/\varepsilon)$ to attain an error of $\varepsilon$ under a variant of restricted eigenvalue condition, and the rate has better dependency on the problem dimension than existing methods. Particularly, if the smallest magnitude of the non-zero components of the optimal solution is not too small, the rate of our proposed {\it Hybrid} algorithm can be boosted to near the minimax optimal sample complexity of {\it full information} algorithms. The core ideas are (i) efficient construction of an unbiased gradient estimator by the iterative usage of the hard thresholding operator for configuring an exploration algorithm; and (ii) an adaptive combination of the exploration and an exploitation algorithms for quickly identifying the support of the optimum and efficiently searching the optimal parameter in its support. Experimental results are presented to validate our theoretical findings and the superiority of our proposed methods.