 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Human Evaluation of Large Language Models via Maximum Discrepancy Competition
Paper and Code



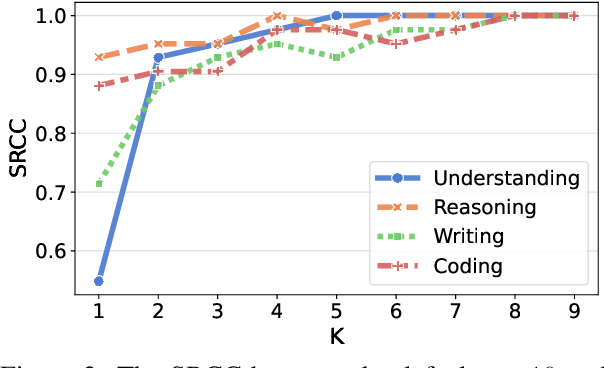
The past years have witnessed a proliferation of large language models (LLMs). Yet, automated and unbiased evaluation of LLMs is challenging due to the inaccuracy of standard metrics in reflecting human preferences and the inefficiency in sampling informative and diverse test examples. While human evaluation remains the gold standard, it is expensive and time-consuming, especially when dealing with a large number of testing samples. To address this problem, we propose a sample-efficient human evaluation method based on MAximum Discrepancy (MAD) competition. MAD automatically selects a small set of informative and diverse instructions, each adapted to two LLMs, whose responses are subject to three-alternative forced choice by human subjects. The pairwise comparison results are then aggregated into a global ranking using the Elo rating system. We select eight representative LLMs and compare them in terms of four skills: knowledge understanding, mathematical reasoning, writing, and coding. Experimental results show that the proposed method achieves a reliable and sensible ranking of LLMs' capabilities, identifies their relative strengths and weaknesses, and offers valuable insights for further LLM advancement.