 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Efficient Deep Reinforcement Learning for Dialogue Systems with Large Action Spaces
Paper and Code
Feb 11, 2018
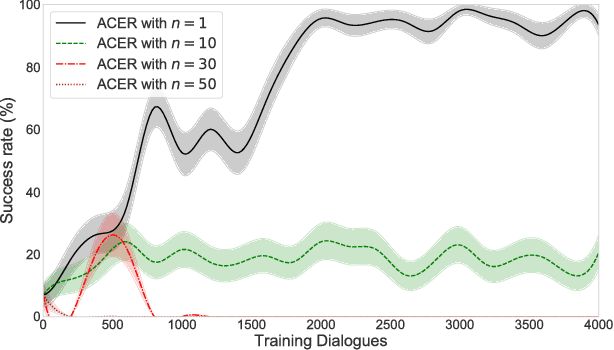
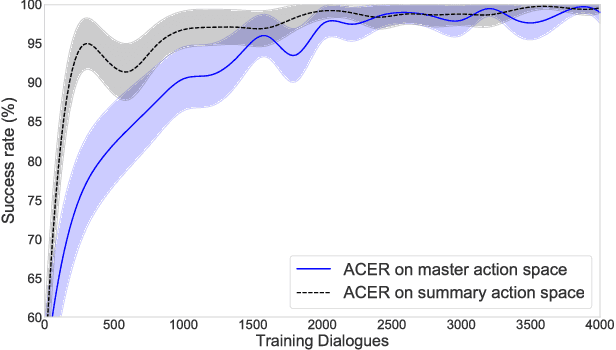
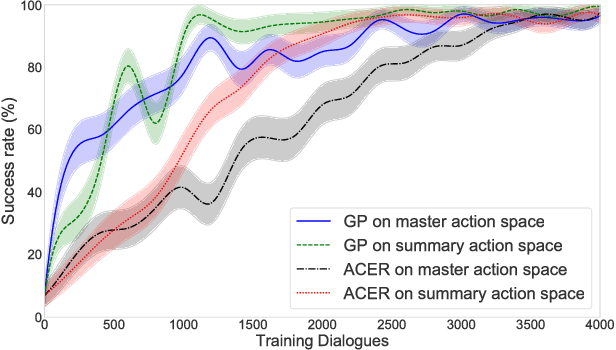
In spoken dialogue systems, we aim to deploy artificial intelligence to build automated dialogue agents that can converse with humans. A part of this effort is the policy optimisation task, which attempts to find a policy describing how to respond to humans, in the form of a function taking the current state of the dialogue and returning the response of the system. In this paper, we investigate deep reinforcement learning approaches to solve this problem. Particular attention is given to actor-critic methods, off-policy reinforcement learning with experience replay, and various methods aimed at reducing the bias and variance of estimators. When combined, these methods result in the previously proposed ACER algorithm that gave competitive results in gaming environments. These environments however are fully observable and have a relatively small action set so in this paper we examine the application of ACER to dialogue policy optimisation. We show that this method beats the current state-of-the-art in deep learning approaches for spoken dialogue systems. This not only leads to a more sample efficient algorithm that can train faster, but also allows us to apply the algorithm in more difficult environments than before. We thus experiment with learning in a very large action space, which has two orders of magnitude more actions than previously considered. We find that ACER trains significantly faster than the current state-of-the-art.