 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Complexity versus Depth: An Information Theoretic Analysis
Paper and Code

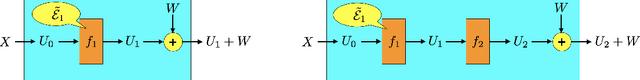
Deep learning has proven effective across a range of data sets. In light of this, a natural inquiry is: "for what data generating processes can deep learning succeed?" In this work, we study the sample complexity of learning multilayer data generating processes of a sort for which deep neural networks seem to be suited. We develop general and elegant information-theoretic tools that accommodate analysis of any data generating process -- shallow or deep, parametric or nonparametric, noiseless or noisy. We then use these tools to characterize the dependence of sample complexity on the depth of multilayer processes. Our results indicate roughly linear dependence on depth. This is in contrast to previous results that suggest exponential or high-order polynomial dependence.