 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Complexity of Bayesian Optimal Dictionary Learning
Paper and Code
Feb 05, 2014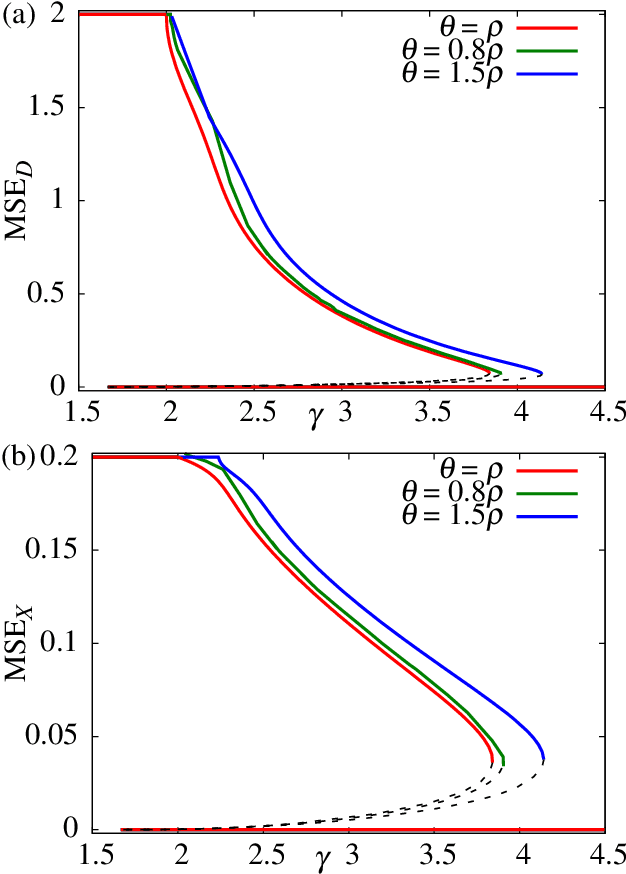
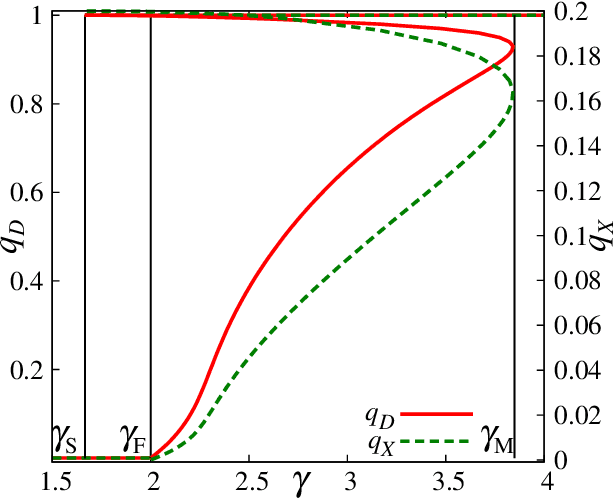
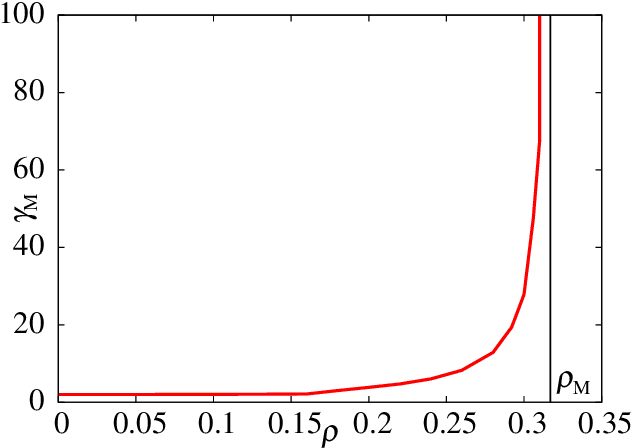
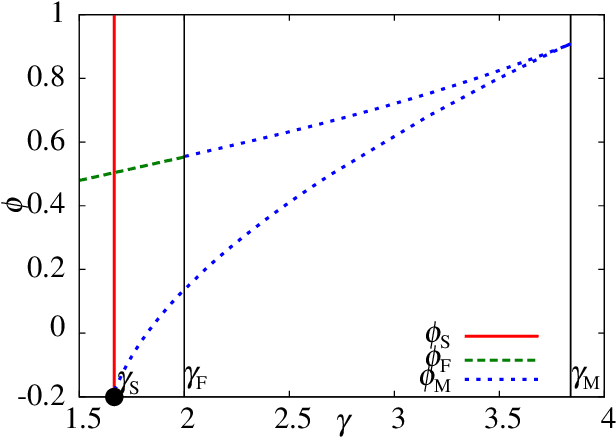
We consider a learning problem of identifying a dictionary matrix D (M times N dimension) from a sample set of M dimensional vectors Y = N^{-1/2} DX, where X is a sparse matrix (N times P dimension) in which the density of non-zero entries is 0<rho< 1. In particular, we focus on the minimum sample size P_c (sample complexity) necessary for perfectly identifying D of the optimal learning scheme when D and X are independently generated from certain distributions. By using the replica method of statistical mechanics, we show that P_c=O(N) holds as long as alpha = M/N >rho is satisfied in the limit of N to infinity. Our analysis also implies that the posterior distribution given Y is condensed only at the correct dictionary D when the compression rate alpha is greater than a certain critical value alpha_M(rho). This suggests that belief propagation may allow us to learn D with a low computational complexity using O(N) samples.