Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaiNet: Stereo aware inpainting behind objects with generative networks
Paper and Code
May 14, 2022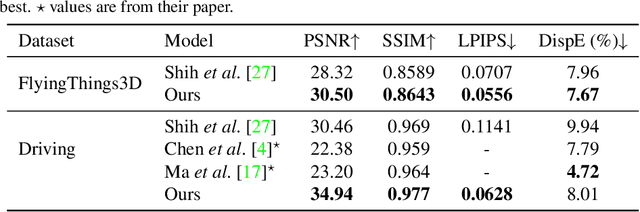
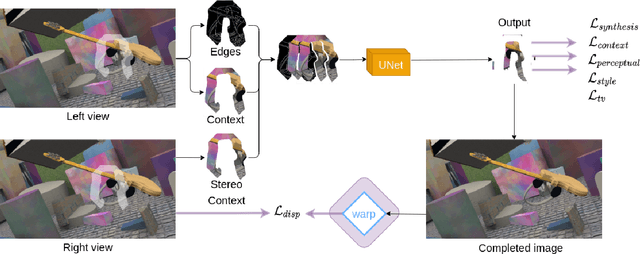


In this work, we present an end-to-end network for stereo-consistent image inpainting with the objective of inpainting large missing regions behind objects. The proposed model consists of an edge-guided UNet-like network using Partial Convolutions. We enforce multi-view stereo consistency by introducing a disparity loss. More importantly, we develop a training scheme where the model is learned from realistic stereo masks representing object occlusions, instead of the more common random masks. The technique is trained in a supervised way. Our evaluation shows competitive results compared to previous state-of-the-art techniques.
* Presented at AI4CC workshop at CVPR
View paper on