 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeRL-Kit: Evaluating Efficient Reinforcement Learning Methods for Safe Autonomous Driving
Paper and Code
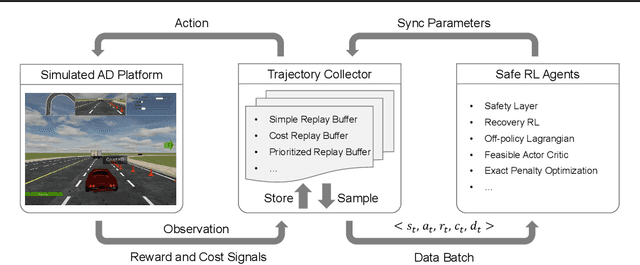



Safe reinforcement learning (RL) has achieved significant success on risk-sensitive tasks and shown promise in autonomous driving (AD) as well. Considering the distinctiveness of this community, efficient and reproducible baselines are still lacking for safe AD. In this paper, we release SafeRL-Kit to benchmark safe RL methods for AD-oriented tasks. Concretely, SafeRL-Kit contains several latest algorithms specific to zero-constraint-violation tasks, including Safety Layer, Recovery RL, off-policy Lagrangian method, and Feasible Actor-Critic. In addition to existing approaches, we propose a novel first-order method named Exact Penalty Optimization (EPO) and sufficiently demonstrate its capability in safe AD. All algorithms in SafeRL-Kit are implemented (i) under the off-policy setting, which improves sample efficiency and can better leverage past logs; (ii) with a unified learning framework, providing off-the-shelf interfaces for researchers to incorporate their domain-specific knowledge into fundamental safe RL methods. Conclusively, we conduct a comparative evaluation of the above algorithms in SafeRL-Kit and shed light on their efficacy for safe autonomous driving. The source code is available at \href{ https://github.com/zlr20/saferl_kit}{this https URL}.