 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAE: Sequential Anchored Ensembles
Paper and Code
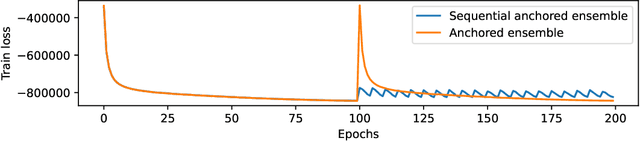
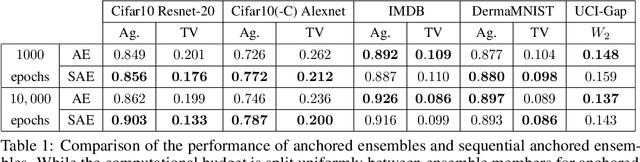
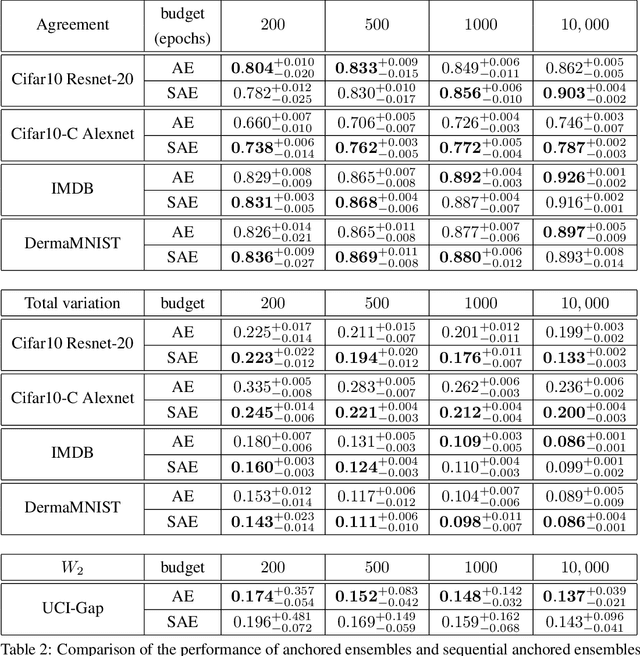
Computing the Bayesian posterior of a neural network is a challenging task due to the high-dimensionality of the parameter space. Anchored ensembles approximate the posterior by training an ensemble of neural networks on anchored losses designed for the optima to follow the Bayesian posterior. Training an ensemble, however, becomes computationally expensive as its number of members grows since the full training procedure is repeated for each member. In this note, we present Sequential Anchored Ensembles (SAE), a lightweight alternative to anchored ensembles. Instead of training each member of the ensemble from scratch, the members are trained sequentially on losses sampled with high auto-correlation, hence enabling fast convergence of the neural networks and efficient approximation of the Bayesian posterior. SAE outperform anchored ensembles, for a given computational budget, on some benchmarks while showing comparable performance on the others and achieved 2nd and 3rd place in the light and extended tracks of the NeurIPS 2021 Approximate Inference in Bayesian Deep Learning competition.