 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAD: Saliency-based Defenses Against Adversarial Examples
Paper and Code
Mar 10, 2020
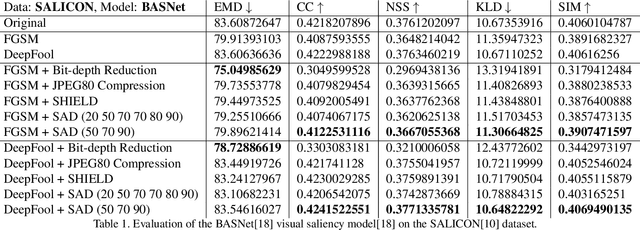
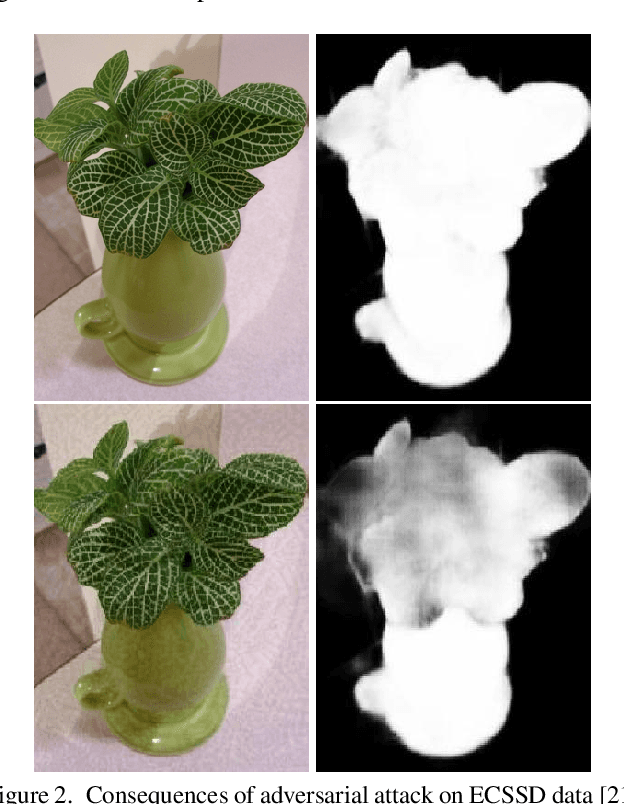
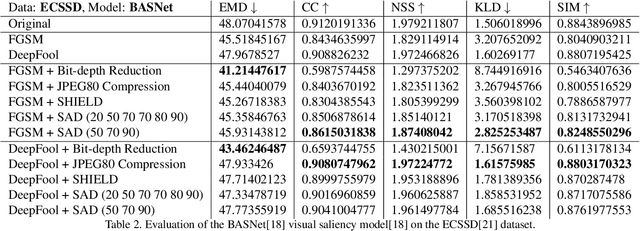
With the rise in popularity of machine and deep learning models, there is an increased focus on their vulnerability to malicious inputs. These adversarial examples drift model predictions away from the original intent of the network and are a growing concern in practical security. In order to combat these attacks, neural networks can leverage traditional image processing approaches or state-of-the-art defensive models to reduce perturbations in the data. Defensive approaches that take a global approach to noise reduction are effective against adversarial attacks, however their lossy approach often distorts important data within the image. In this work, we propose a visual saliency based approach to cleaning data affected by an adversarial attack. Our model leverages the salient regions of an adversarial image in order to provide a targeted countermeasure while comparatively reducing loss within the cleaned images. We measure the accuracy of our model by evaluating the effectiveness of state-of-the-art saliency methods prior to attack, under attack, and after application of cleaning methods. We demonstrate the effectiveness of our proposed approach in comparison with related defenses and against established adversarial attack methods, across two saliency datasets. Our targeted approach shows significant improvements in a range of standard statistical and distance saliency metrics, in comparison with both traditional and state-of-the-art approaches.