 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRun Procrustes, Run! On the convergence of accelerated Procrustes Flow
Paper and Code
Sep 12, 2018
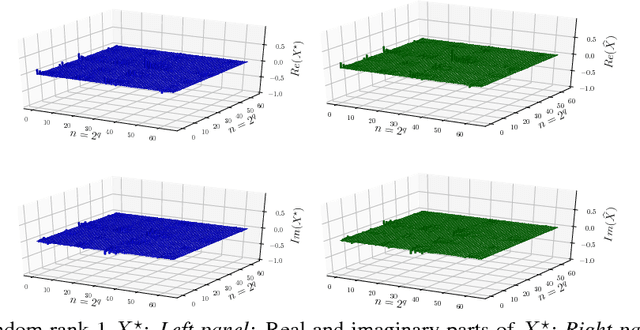
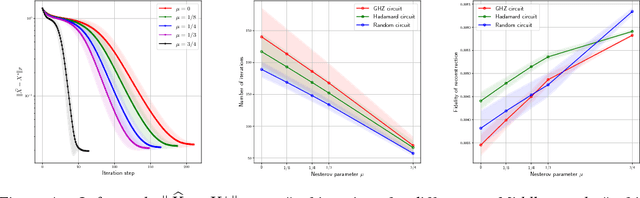
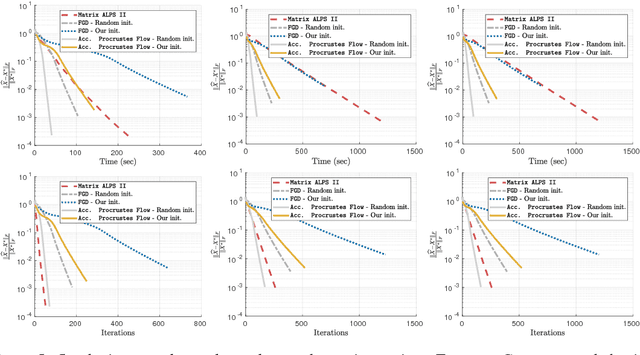
In this work, we present theoretical results on the convergence of non-convex accelerated gradient descent in matrix factorization models. The technique is applied to matrix sensing problems with squared loss, for the estimation of a rank $r$ optimal solution $X^\star \in \mathbb{R}^{n \times n}$. We show that the acceleration leads to linear convergence rate, even under non-convex settings where the variable $X$ is represented as $U U^\top$ for $U \in \mathbb{R}^{n \times r}$. Our result has the same dependence on the condition number of the objective --and the optimal solution-- as that of the recent results on non-accelerated algorithms. However, acceleration is observed in practice, both in synthetic examples and in two real applications: neuronal multi-unit activities recovery from single electrode recordings, and quantum state tomography on quantum computing simulators.