 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouterBench: A Benchmark for Multi-LLM Routing System
Paper and Code
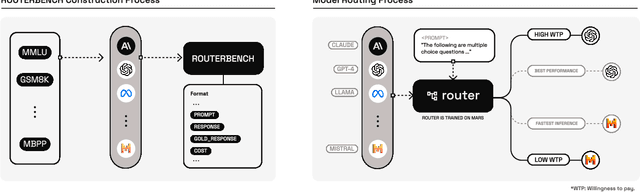
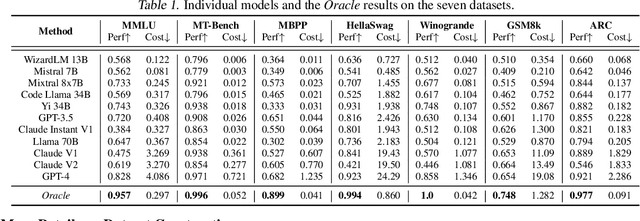
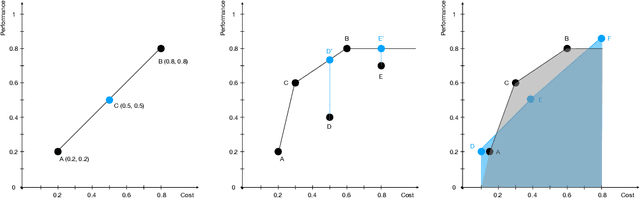
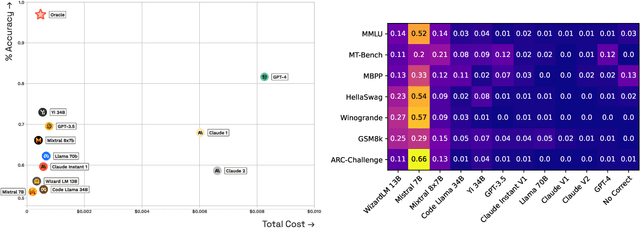
As the range of applications for Large Language Models (LLMs) continues to grow, the demand for effective serving solutions becomes increasingly critical. Despite the versatility of LLMs, no single model can optimally address all tasks and applications, particularly when balancing performance with cost. This limitation has led to the development of LLM routing systems, which combine the strengths of various models to overcome the constraints of individual LLMs. Yet, the absence of a standardized benchmark for evaluating the performance of LLM routers hinders progress in this area. To bridge this gap, we present RouterBench, a novel evaluation framework designed to systematically assess the efficacy of LLM routing systems, along with a comprehensive dataset comprising over 405k inference outcomes from representative LLMs to support the development of routing strategies. We further propose a theoretical framework for LLM routing, and deliver a comparative analysis of various routing approaches through RouterBench, highlighting their potentials and limitations within our evaluation framework. This work not only formalizes and advances the development of LLM routing systems but also sets a standard for their assessment, paving the way for more accessible and economically viable LLM deployments. The code and data are available at https://github.com/withmartian/routerbench.