 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRole-Play Zero-Shot Prompting with Large Language Models for Open-Domain Human-Machine Conversation
Paper and Code
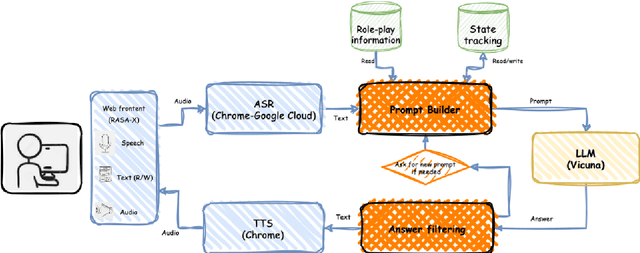
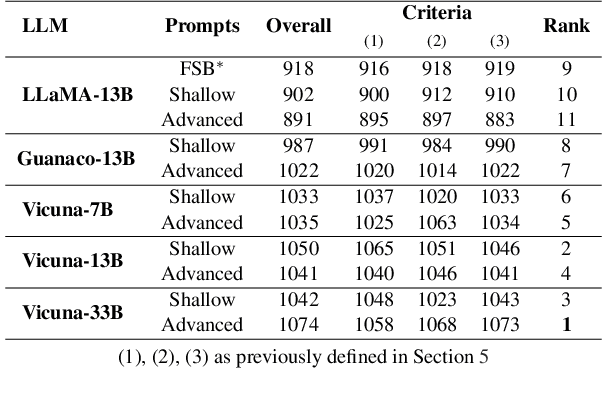

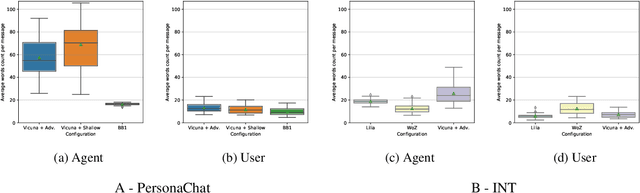
Recently, various methods have been proposed to create open-domain conversational agents with Large Language Models (LLMs). These models are able to answer user queries, but in a one-way Q&A format rather than a true conversation. Fine-tuning on particular datasets is the usual way to modify their style to increase conversational ability, but this is expensive and usually only available in a few languages. In this study, we explore role-play zero-shot prompting as an efficient and cost-effective solution for open-domain conversation, using capable multilingual LLMs (Beeching et al., 2023) trained to obey instructions. We design a prompting system that, when combined with an instruction-following model - here Vicuna (Chiang et al., 2023) - produces conversational agents that match and even surpass fine-tuned models in human evaluation in French in two different tasks.