 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Tuning Datasets for Statistical Machine Translation
Paper and Code
Oct 01, 2017
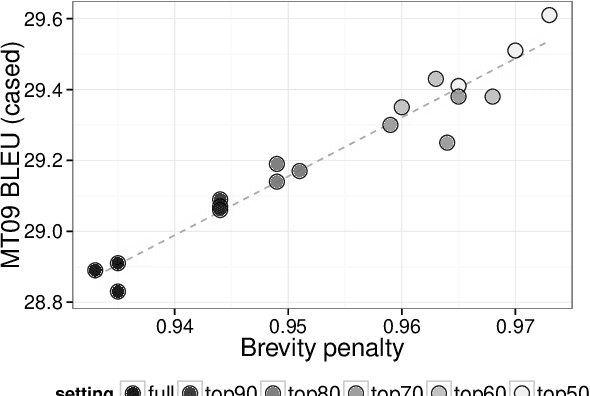
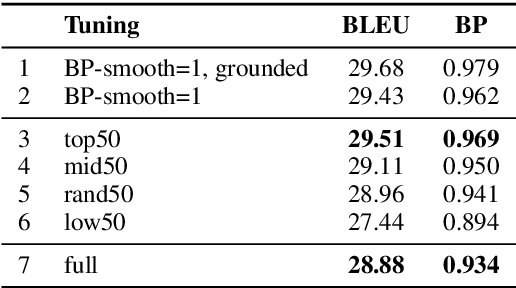
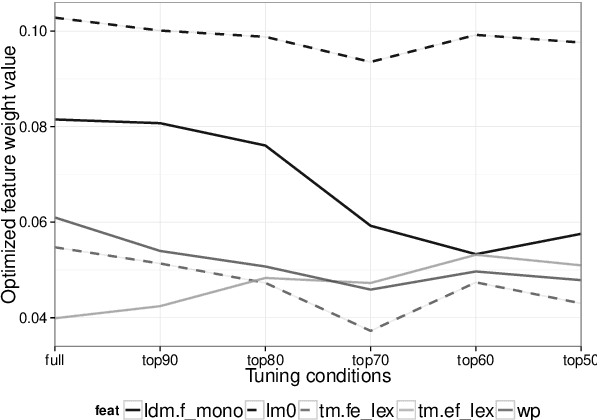
We explore the idea of automatically crafting a tuning dataset for Statistical Machine Translation (SMT) that makes the hyper-parameters of the SMT system more robust with respect to some specific deficiencies of the parameter tuning algorithms. This is an under-explored research direction, which can allow better parameter tuning. In this paper, we achieve this goal by selecting a subset of the available sentence pairs, which are more suitable for specific combinations of optimizers, objective functions, and evaluation measures. We demonstrate the potential of the idea with the pairwise ranking optimization (PRO) optimizer, which is known to yield too short translations. We show that the learning problem can be alleviated by tuning on a subset of the development set, selected based on sentence length. In particular, using the longest 50% of the tuning sentences, we achieve two-fold tuning speedup, and improvements in BLEU score that rival those of alternatives, which fix BLEU+1's smoothing instead.