 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Speaker Recognition Using Speech Enhancement And Attention Model
Paper and Code
Jan 14, 2020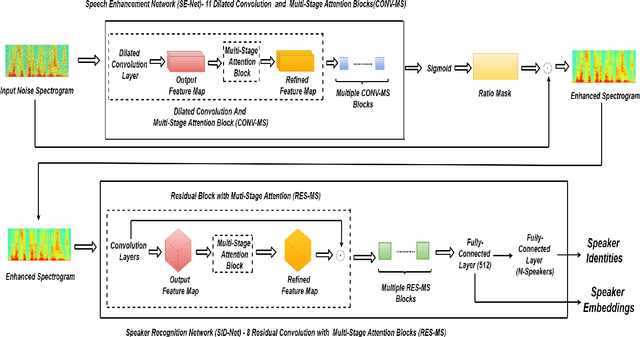

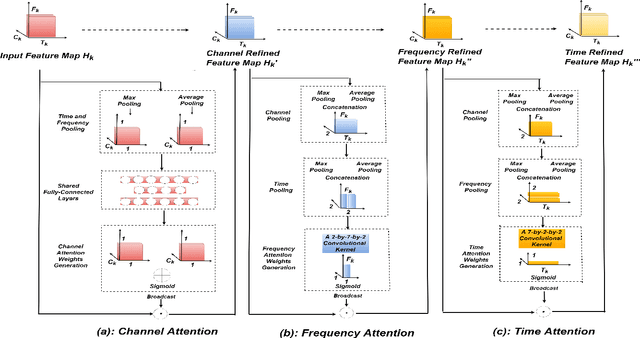
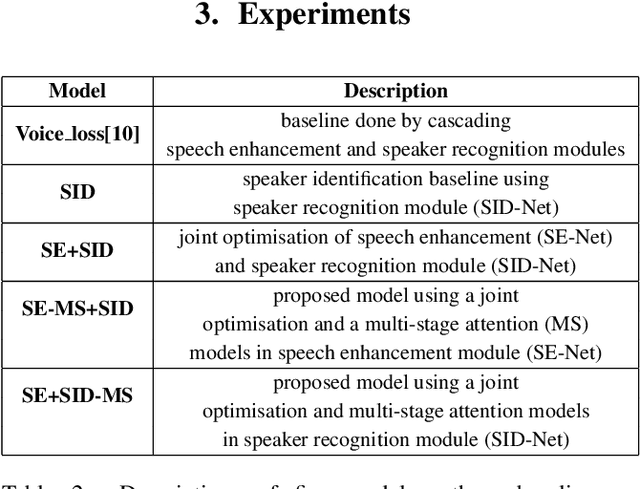
In this paper, a novel architecture for speaker recognition is proposed by cascading speech enhancement and speaker processing. Its aim is to improve speaker recognition performance when speech signals are corrupted by noise. Instead of individually processing speech enhancement and speaker recognition, the two modules are integrated into one framework by a joint optimisation using deep neural networks. Furthermore, to increase robustness against noise, a multi-stage attention mechanism is employed to highlight the speaker related features learned from context information in time and frequency domain. To evaluate speaker identification and verification performance of the proposed approach, we test it on the dataset of VoxCeleb1, one of mostly used benchmark datasets. Moreover, the robustness of our proposed approach is also tested on VoxCeleb1 data when being corrupted by three types of interferences, general noise, music, and babble, at different signal-to-noise ratio (SNR) levels. The obtained results show that the proposed approach using speech enhancement and multi-stage attention models outperforms two strong baselines not using them in most acoustic conditions in our experiments.