 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multi-Agent Bandits Over Undirected Graphs
Paper and Code
Feb 28, 2022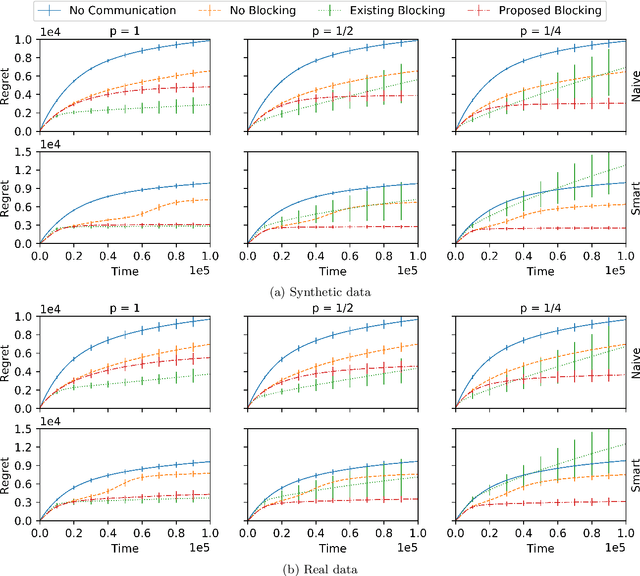
We consider a multi-agent multi-armed bandit setting in which $n$ honest agents collaborate over a network to minimize regret but $m$ malicious agents can disrupt learning arbitrarily. Assuming the network is the complete graph, existing algorithms incur $O( (m + K/n) \log (T) / \Delta )$ regret in this setting, where $K$ is the number of arms and $\Delta$ is the arm gap. For $m \ll K$, this improves over the single-agent baseline regret of $O(K\log(T)/\Delta)$. In this work, we show the situation is murkier beyond the case of a complete graph. In particular, we prove that if the state-of-the-art algorithm is used on the undirected line graph, honest agents can suffer (nearly) linear regret until time is doubly exponential in $K$ and $n$. In light of this negative result, we propose a new algorithm for which the $i$-th agent has regret $O( ( d_{\text{mal}}(i) + K/n) \log(T)/\Delta)$ on any connected and undirected graph, where $d_{\text{mal}}(i)$ is the number of $i$'s neighbors who are malicious. Thus, we generalize existing regret bounds beyond the complete graph (where $d_{\text{mal}}(i) = m$), and show the effect of malicious agents is entirely local (in the sense that only the $d_{\text{mal}}(i)$ malicious agents directly connected to $i$ affect its long-term regret).