 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust methods for high-dimensional linear learning
Paper and Code
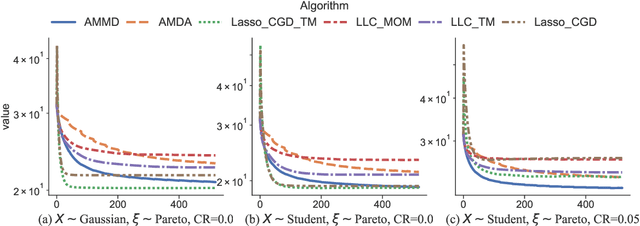
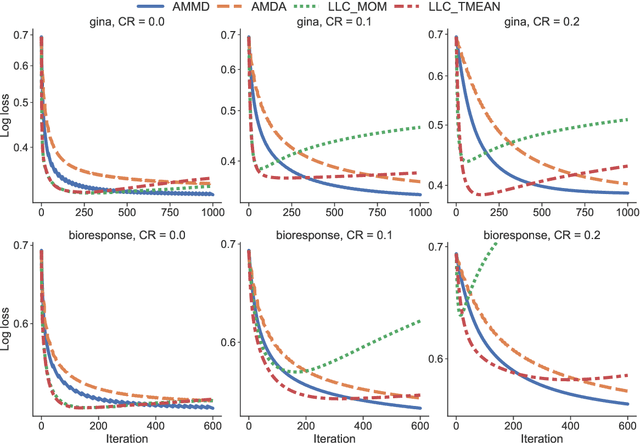
We propose statistically robust and computationally efficient linear learning methods in the high-dimensional batch setting, where the number of features $d$ may exceed the sample size $n$. We employ, in a generic learning setting, two algorithms depending on whether the considered loss function is gradient-Lipschitz or not. Then, we instantiate our framework on several applications including vanilla sparse, group-sparse and low-rank matrix recovery. This leads, for each application, to efficient and robust learning algorithms, that reach near-optimal estimation rates under heavy-tailed distributions and the presence of outliers. For vanilla $s$-sparsity, we are able to reach the $s\log (d)/n$ rate under heavy-tails and $\eta$-corruption, at a computational cost comparable to that of non-robust analogs. We provide an efficient implementation of our algorithms in an open-source $\mathtt{Python}$ library called $\mathtt{linlearn}$, by means of which we carry out numerical experiments which confirm our theoretical findings together with a comparison to other recent approaches proposed in the literature.