 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Loss Functions under Label Noise for Deep Neural Networks
Paper and Code
Dec 27, 2017
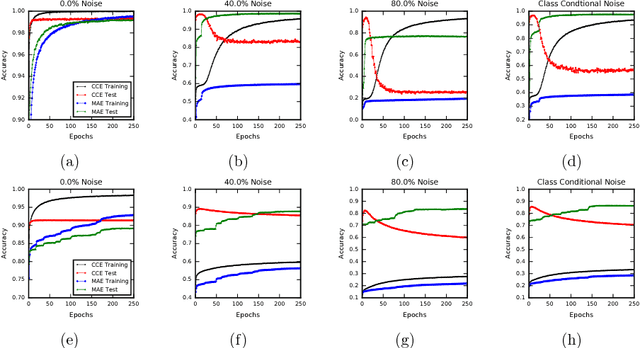
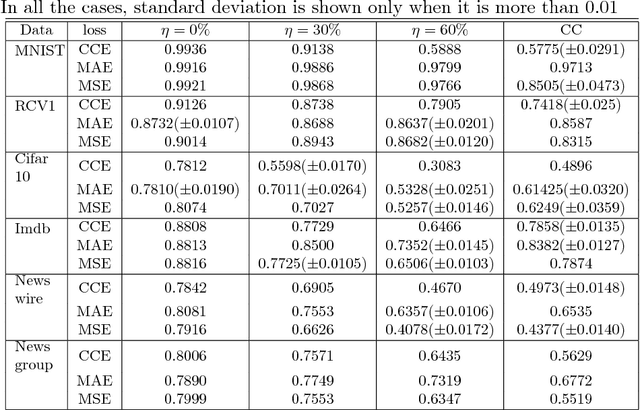
In many applications of classifier learning, training data suffers from label noise. Deep networks are learned using huge training data where the problem of noisy labels is particularly relevant. The current techniques proposed for learning deep networks under label noise focus on modifying the network architecture and on algorithms for estimating true labels from noisy labels. An alternate approach would be to look for loss functions that are inherently noise-tolerant. For binary classification there exist theoretical results on loss functions that are robust to label noise. In this paper, we provide some sufficient conditions on a loss function so that risk minimization under that loss function would be inherently tolerant to label noise for multiclass classification problems. These results generalize the existing results on noise-tolerant loss functions for binary classification. We study some of the widely used loss functions in deep networks and show that the loss function based on mean absolute value of error is inherently robust to label noise. Thus standard back propagation is enough to learn the true classifier even under label noise. Through experiments, we illustrate the robustness of risk minimization with such loss functions for learning neural networks.