 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and interpretable blind image denoising via bias-free convolutional neural networks
Paper and Code
Jun 14, 2019
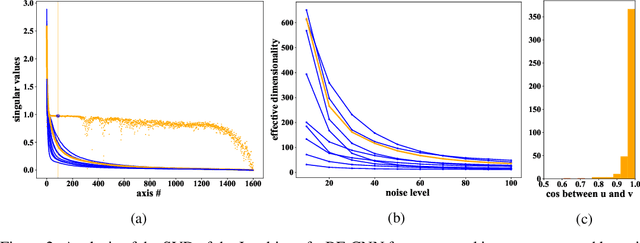

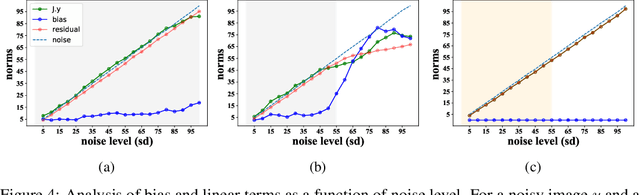
Deep convolutional networks often append additive constant ("bias") terms to their convolution operations, enabling a richer repertoire of functional mappings. Biases are also used to facilitate training, by subtracting mean response over batches of training images (a component of "batch normalization"). Recent state-of-the-art blind denoising methods (e.g., DnCNN) seem to require these terms for their success. Here, however, we show that these networks systematically overfit the noise levels for which they are trained: when deployed at noise levels outside the training range, performance degrades dramatically. In contrast, a bias-free architecture -- obtained by removing the constant terms in every layer of the network, including those used for batch normalization-- generalizes robustly across noise levels, while preserving state-of-the-art performance within the training range. Locally, the bias-free network acts linearly on the noisy image, enabling direct analysis of network behavior via standard linear-algebraic tools. These analyses provide interpretations of network functionality in terms of nonlinear adaptive filtering, and projection onto a union of low-dimensional subspaces, connecting the learning-based method to more traditional denoising methodology.