 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Automatic Data Clustering: Dirichlet Process meets Median-of-Means
Paper and Code
Nov 26, 2023


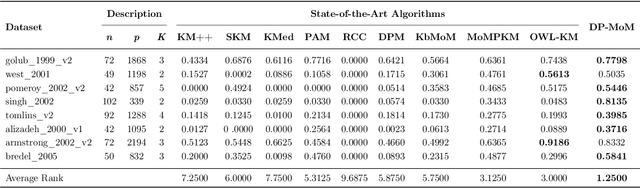
Clustering stands as one of the most prominent challenges within the realm of unsupervised machine learning. Among the array of centroid-based clustering algorithms, the classic $k$-means algorithm, rooted in Lloyd's heuristic, takes center stage as one of the extensively employed techniques in the literature. Nonetheless, both $k$-means and its variants grapple with noteworthy limitations. These encompass a heavy reliance on initial cluster centroids, susceptibility to converging into local minima of the objective function, and sensitivity to outliers and noise in the data. When confronted with data containing noisy or outlier-laden observations, the Median-of-Means (MoM) estimator emerges as a stabilizing force for any centroid-based clustering framework. On a different note, a prevalent constraint among existing clustering methodologies resides in the prerequisite knowledge of the number of clusters prior to analysis. Utilizing model-based methodologies, such as Bayesian nonparametric models, offers the advantage of infinite mixture models, thereby circumventing the need for such requirements. Motivated by these facts, in this article, we present an efficient and automatic clustering technique by integrating the principles of model-based and centroid-based methodologies that mitigates the effect of noise on the quality of clustering while ensuring that the number of clusters need not be specified in advance. Statistical guarantees on the upper bound of clustering error, and rigorous assessment through simulated and real datasets suggest the advantages of our proposed method over existing state-of-the-art clustering algorithms.