 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRivalry of Two Families of Algorithms for Memory-Restricted Streaming PCA
Paper and Code
Oct 12, 2015
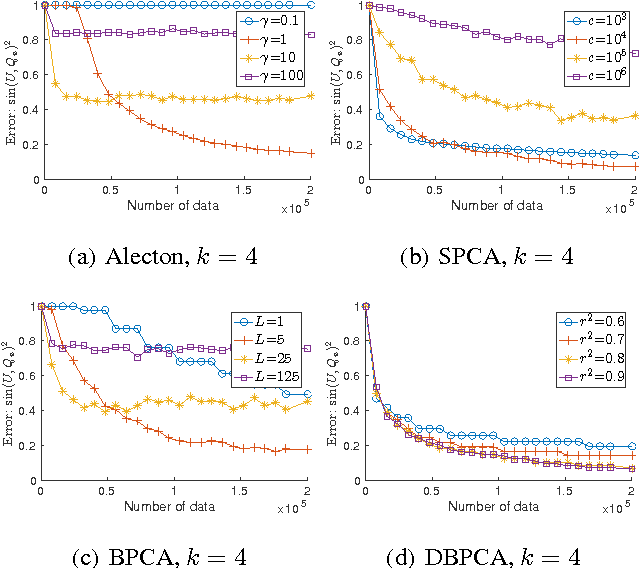
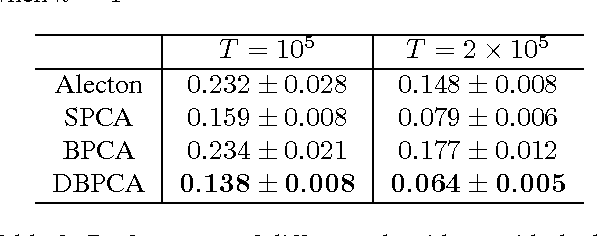
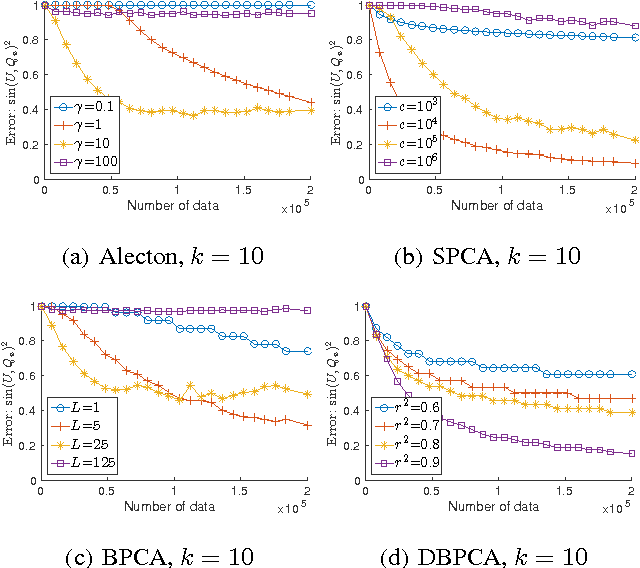
We study the problem of recovering the subspace spanned by the first $k$ principal components of $d$-dimensional data under the streaming setting, with a memory bound of $O(kd)$. Two families of algorithms are known for this problem. The first family is based on the framework of stochastic gradient descent. Nevertheless, the convergence rate of the family can be seriously affected by the learning rate of the descent steps and deserves more serious study. The second family is based on the power method over blocks of data, but setting the block size for its existing algorithms is not an easy task. In this paper, we analyze the convergence rate of a representative algorithm with decayed learning rate (Oja and Karhunen, 1985) in the first family for the general $k>1$ case. Moreover, we propose a novel algorithm for the second family that sets the block sizes automatically and dynamically with faster convergence rate. We then conduct empirical studies that fairly compare the two families on real-world data. The studies reveal the advantages and disadvantages of these two families.