 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Constrained Thompson Sampling for CVaR Bandits
Paper and Code
Nov 17, 2020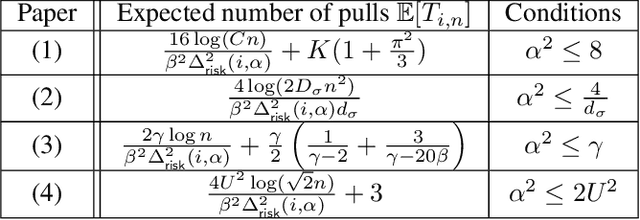
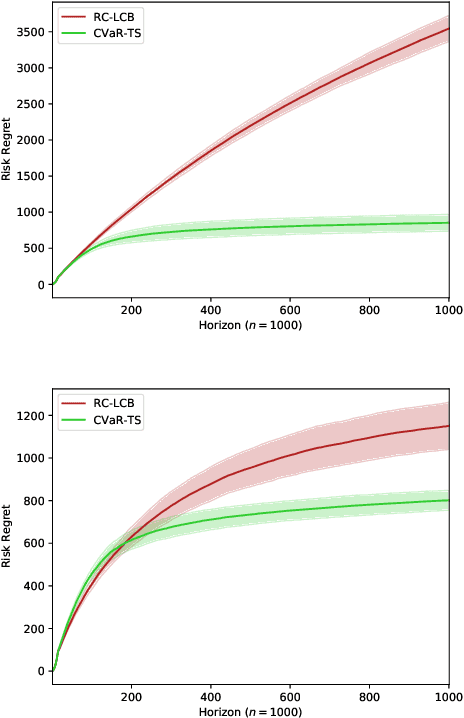

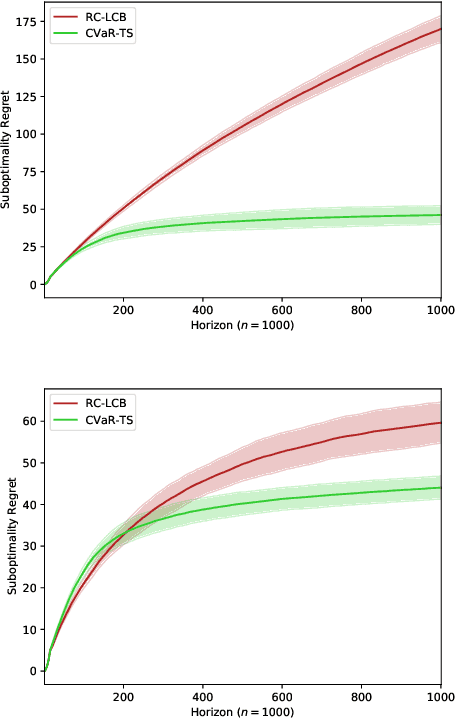
The multi-armed bandit (MAB) problem is a ubiquitous decision-making problem that exemplifies the exploration-exploitation tradeoff. Standard formulations exclude risk in decision making. Risk notably complicates the basic reward-maximising objective, in part because there is no universally agreed definition of it. In this paper, we consider a popular risk measure in quantitative finance known as the Conditional Value at Risk (CVaR). We explore the performance of a Thompson Sampling-based algorithm CVaR-TS under this risk measure. We provide comprehensive comparisons between our regret bounds with state-of-the-art L/UCB-based algorithms in comparable settings and demonstrate their clear improvement in performance. We also include numerical simulations to empirically verify that CVaR-TS outperforms other L/UCB-based algorithms.