 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIDDLE: Race and ethnicity Imputation from Disease history with Deep LEarning
Paper and Code
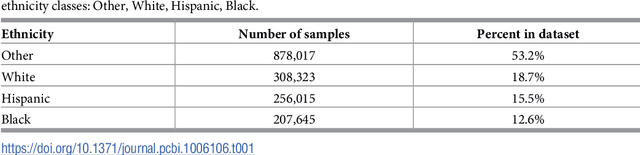
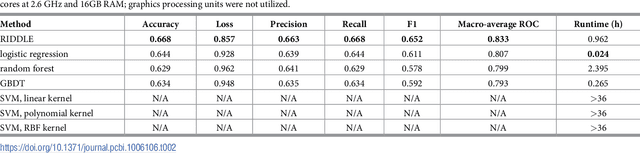
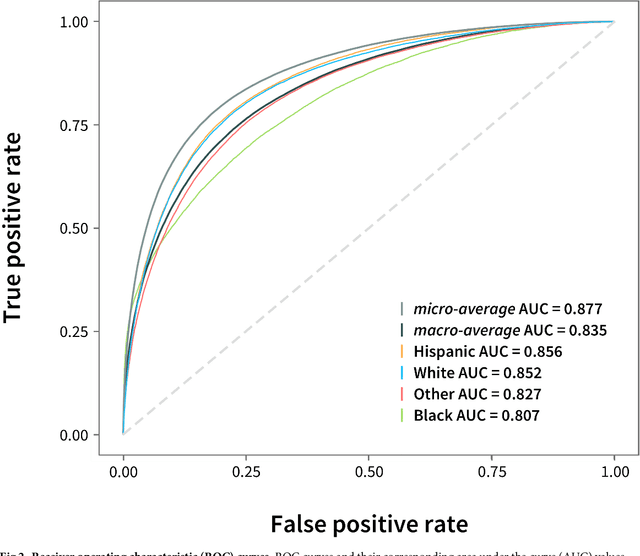
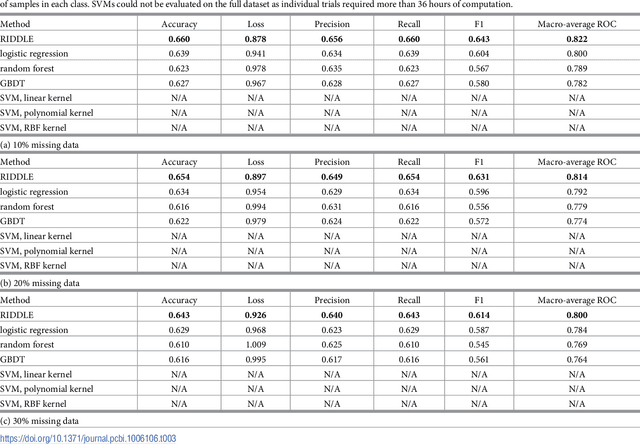
Anonymized electronic medical records are an increasingly popular source of research data. However, these datasets often lack race and ethnicity information. This creates problems for researchers modeling human disease, as race and ethnicity are powerful confounders for many health exposures and treatment outcomes; race and ethnicity are closely linked to population-specific genetic variation. We showed that deep neural networks generate more accurate estimates for missing racial and ethnic information than competing methods (e.g., logistic regression, random forest). RIDDLE yielded significantly better classification performance across all metrics that were considered: accuracy, cross-entropy loss (error), and area under the curve for receiver operating characteristic plots (all $p < 10^{-6}$). We made specific efforts to interpret the trained neural network models to identify, quantify, and visualize medical features which are predictive of race and ethnicity. We used these characterizations of informative features to perform a systematic comparison of differential disease patterns by race and ethnicity. The fact that clinical histories are informative for imputing race and ethnicity could reflect (1) a skewed distribution of blue- and white-collar professions across racial and ethnic groups, (2) uneven accessibility and subjective importance of prophylactic health, (3) possible variation in lifestyle, such as dietary habits, and (4) differences in background genetic variation which predispose to diseases.