 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRich Character-Level Information for Korean Morphological Analysis and Part-of-Speech Tagging
Paper and Code


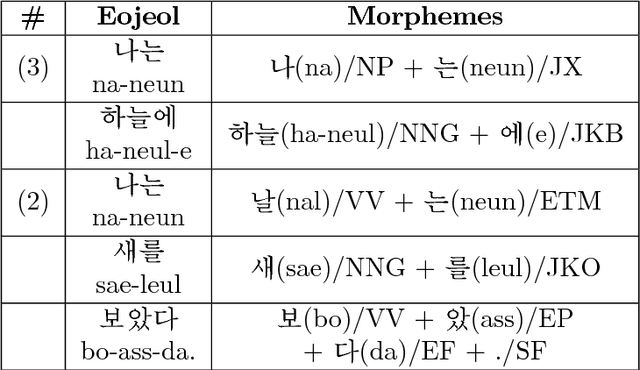
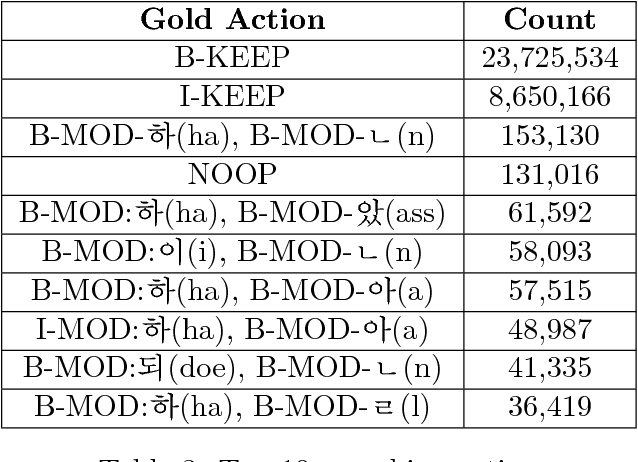
Due to the fact that Korean is a highly agglutinative, character-rich language, previous work on Korean morphological analysis typically employs the use of sub-character features known as graphemes or otherwise utilizes comprehensive prior linguistic knowledge (i.e., a dictionary of known morphological transformation forms, or actions). These models have been created with the assumption that character-level, dictionary-less morphological analysis was intractable due to the number of actions required. We present, in this study, a multi-stage action-based model that can perform morphological transformation and part-of-speech tagging using arbitrary units of input and apply it to the case of character-level Korean morphological analysis. Among models that do not employ prior linguistic knowledge, we achieve state-of-the-art word and sentence-level tagging accuracy with the Sejong Korean corpus using our proposed data-driven Bi-LSTM model.