 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Contextual Toxicity Detection in Conversations
Paper and Code

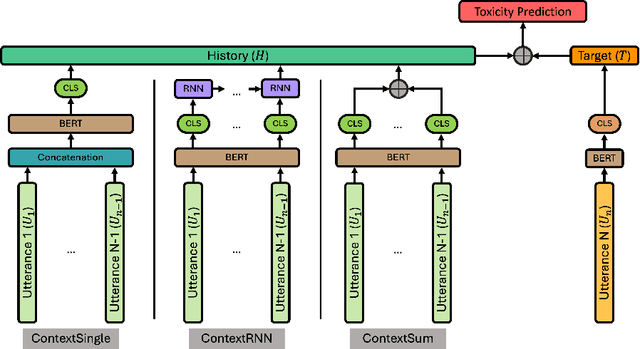

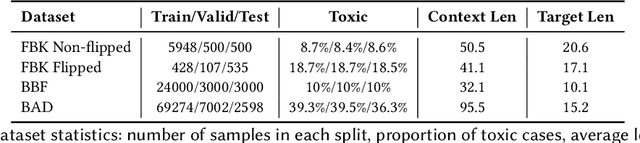
Understanding toxicity in user conversations is undoubtedly an important problem. As it has been argued in previous work, addressing "covert" or implicit cases of toxicity is particularly hard and requires context. Very few previous studies have analysed the influence of conversational context in human perception or in automated detection models. We dive deeper into both these directions. We start by analysing existing contextual datasets and come to the conclusion that toxicity labelling by humans is in general influenced by the conversational structure, polarity and topic of the context. We then propose to bring these findings into computational detection models by introducing (a) neural architectures for contextual toxicity detection that are aware of the conversational structure, and (b) data augmentation strategies that can help model contextual toxicity detection. Our results have shown the encouraging potential of neural architectures that are aware of the conversation structure. We have also demonstrated that such models can benefit from synthetic data, especially in the social media domain.